 Eseandre Mordi
Eseandre Mordi

⬤ Tencent-Hunyuan just dropped GradLoc, a diagnostic tool built to tackle training instability in massive reasoning models. The system pinpoints the exact token causing crashes during early training through a structured multi-phase binary search. The framework diagram maps out how it goes from global gradient checks down to token-level isolation, hitting O(M + log(N)) complexity. This fits into the bigger picture of model orchestration innovation, much like what we've seen with Sentient's ROMA open-source multi-agent framework.
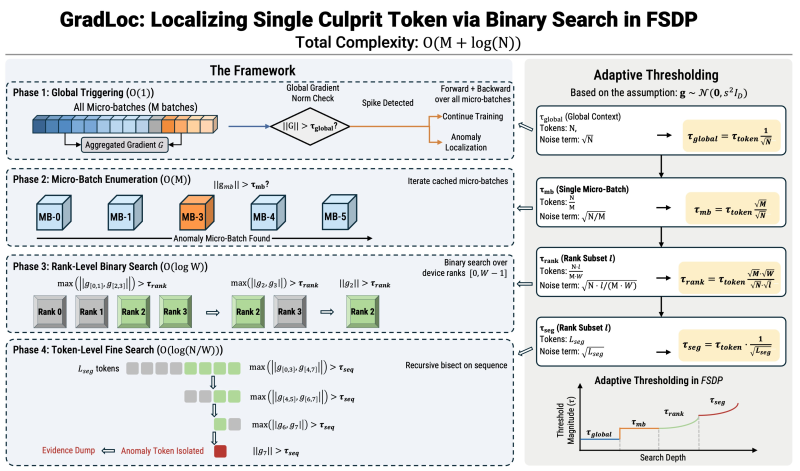
⬤ The GradLoc pipeline kicks off with a global gradient norm check across all micro-batches. When it spots an anomaly spike, the system runs micro-batch enumeration to find the problem subset, then does a rank-level binary search across distributed devices. The final step is a token-level fine search that nails down the single "culprit token." This step-by-step narrowing turns mysterious training crashes into events you can actually trace and fix, making large-scale distributed training way more transparent.
⬤ After detection, Tencent-Hunyuan built LayerClip to stabilize things. Instead of using one global threshold, LayerClip brings adaptive thresholding customized for each layer and token segment. The diagram shows how thresholds shift from global context to micro-batch and then down to token-level segments. This adaptive approach stops harmful gradient spikes while keeping healthy signals flowing. The push for these stability tools mirrors broader AI infrastructure growth, including semiconductor expansion fueled by training workloads - something we're tracking in AI boom pushes US semiconductor market share above 32%.
⬤ GradLoc and LayerClip highlight the growing focus on reliability and fault isolation in large-scale AI training. As reasoning models get bigger and more complex, token-level diagnostic tools and adaptive stabilization techniques are becoming critical for maintaining consistent training performance across distributed setups.
 Eseandre Mordi
Eseandre Mordi


