 Peter Smith
Peter Smith

A new testing framework is putting AI research agents under the microscope, and the results aren't pretty. Researchers have built MMDeepResearch-Bench to see if AI can actually back up its claims with solid visual and text evidence - and most models are falling short.
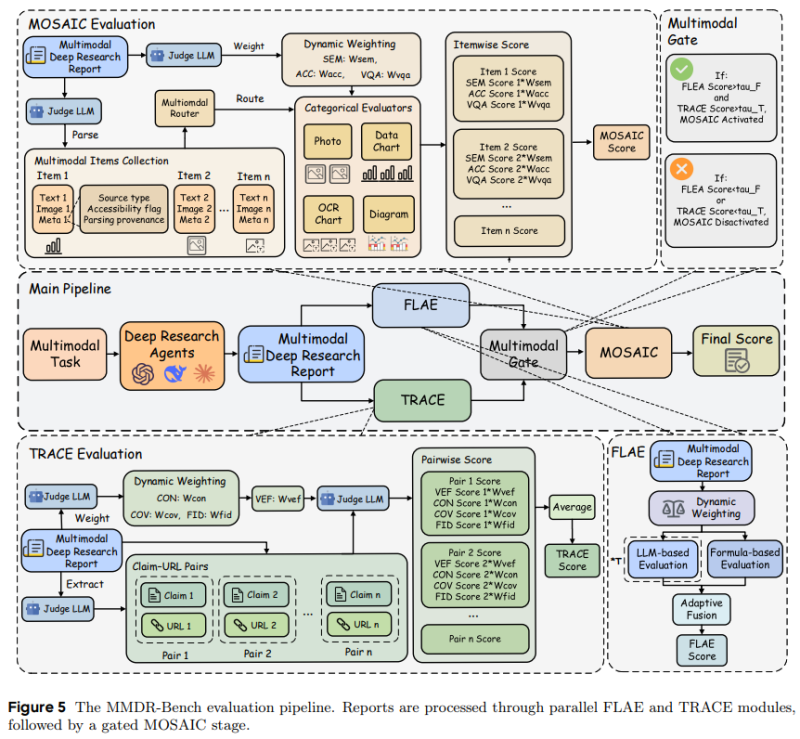
What MMDeepResearch-Bench Actually Tests
Researchers from Oregon State University, Amazon, the University of Michigan, and several international partners just dropped MMDeepResearch-Bench - a benchmark that checks whether AI research agents can pull together deep, evidence-based reports mixing text and visuals. The benchmark throws 140 expert-designed tasks across 21 different fields at these models, testing whether they can keep their citations straight and properly ground claims in visual data. This work ties into bigger conversations about AI reliability, similar to recent research into how AI assistance shapes coding skills in practice, which shows how model behavior plays out differently across various tasks.
How the Scoring System Works
The benchmark runs outputs through a structured pipeline using FLAE, TRACE, and a gated MOSAIC stage to calculate the final multimodal score. It breaks down research reports into text and images, then routes everything through evaluators checking semantic alignment with diagrams, photos, and data charts. The system weighs different category scores dynamically and uses multimodal gating to decide whether final scoring should include both text and visual metrics - basically making sure what the AI writes actually matches the evidence it's citing.
The Results: Fluent Writing Doesn't Mean Accurate Citations
Testing 25 cutting-edge models revealed a troubling pattern - many generate smooth, well-organized writing but consistently fail to properly connect visual data to their claims. Just because an AI writes well doesn't mean it's backing up what it says with real evidence. This mirrors trends we're seeing elsewhere in AI development, where improvements in one area don't automatically translate to strength across complex, multi-format tasks. Similar challenges show up in multiagent systems like the ROMA open-source framework for multi-agent AI development.
Why This Matters for AI Development
MMDeepResearch-Bench highlights a growing push for AI evaluation that goes beyond just generating text to include visual and evidentiary coherence. As AI spreads into research and enterprise use, benchmarks exposing these cross-modal gaps could reshape how developers prioritize future model improvements and allocate resources. These shifts are happening alongside broader market moves in AI infrastructure, like Google leading with 927 MW as Amazon-backed Anthropic claims second in the AI data center power race.
 Peter Smith
Peter Smith


