 Eseandre Mordi
Eseandre Mordi

The AI race continues to heat up as newer models challenge established players in specific domains. Z.AI's latest release, GLM-5, has made waves by outperforming several prominent models in coding and data-analysis tasks, proving that specialized optimization can rival sheer scale.
GLM-5 Delivers Strong Coding Performance
Z.AI's GLM-5 has shown surprisingly competitive results on the LiveBench benchmark, with particularly strong showings in developer-focused categories. The model managed to outpace both Sonnet 4.5 and GPT-5.1-Codex in key metrics.
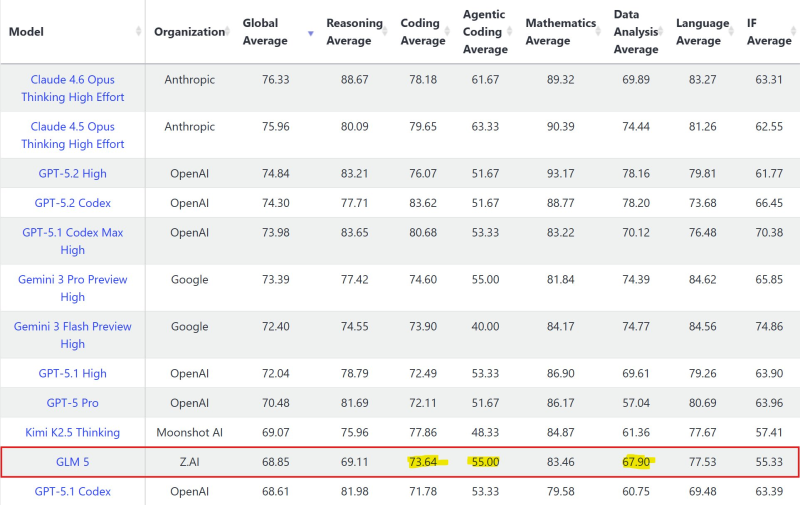
The numbers tell an interesting story. GLM-5 scored 73.64 in coding tasks, 55.00 in agentic coding, and 67.90 in data analysis. These results put it roughly neck-and-neck with Kimi-K2.5 Thinking while pulling ahead of certain competitors in programming-specific workloads.
Specialized Excellence Over Broad Dominance
What makes GLM-5's performance noteworthy isn't necessarily its overall benchmark ranking—it still sits below several frontier models in global average scores. Instead, it's the model's focused strength in coding and analytical operations that stands out.
This pattern reflects a broader trend in AI model development: newer systems are increasingly optimized for specific use cases rather than trying to dominate every category. For developers and data scientists, a model that excels at programming tasks might be more valuable than one with higher general scores but weaker coding capabilities.
What This Means for Developers
The results highlight an important shift in how we should evaluate AI models. Raw benchmark scores don't always tell the full story—task-specific efficiency matters, especially for practical applications.
GLM-5's ability to punch above its weight in coding benchmarks and data analysis tasks suggests that Z.AI prioritized developer workflows during training. This approach could make it a compelling choice for teams focused on software development, even if it doesn't lead every general-purpose leaderboard.
The competitive landscape continues to evolve rapidly, with models like GLM-5 proving that strategic specialization can deliver real-world value. For developers evaluating which AI tools to integrate into their workflows, these targeted capabilities may matter more than overall rankings.
 Eseandre Mordi
Eseandre Mordi


