 Victoria Bazir
Victoria Bazir

French AI company Mistral has expanded its model lineup with the Ministral 3 family, releasing three variants that promise enterprise-grade performance without the typical resource overhead. The new models represent a shift toward more accessible AI systems that can run efficiently across diverse computing environments.
Cascade Distillation Powers 14B, 8B and 3B Model Variants
Mistral recently dropped the open-weight Ministral 3 model family, introducing 14B, 8B, and 3B parameter versions to the market. According to DeepLearning.AI the company compressed these models from a much larger system using a specialized technique called cascade distillation—a method that combines pruning and knowledge transfer.
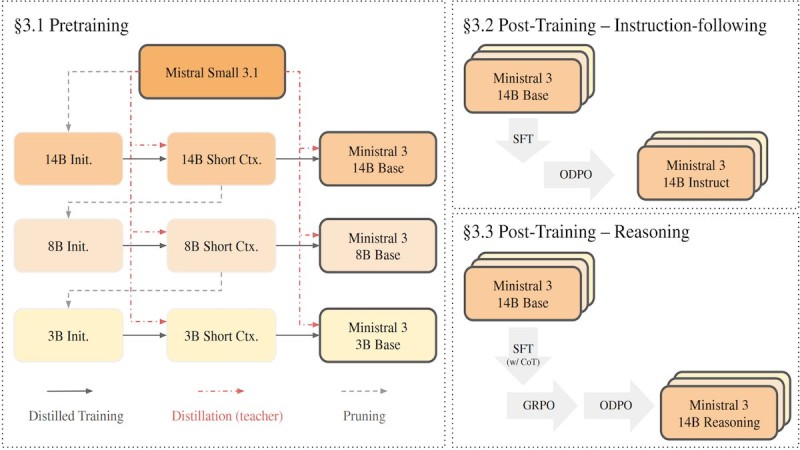
The process works through a staged pipeline where a powerful teacher model passes its capabilities down to progressively smaller student models. This approach differs from traditional compression methods by maintaining performance quality even as model size shrinks dramatically.
How the Training Process Works
The pretraining phase kicks things off by transferring core capabilities from the larger source model into smaller architectures. Based on Mistral's documentation, these initial models go through a short context stage before becoming the Ministral 3 base models at each parameter level. The whole setup is engineered to keep performance solid while slashing both model scale and the computing power needed to run them.
The method is designed to preserve performance while reducing model scale and computational requirements.
After the base models are ready, post-training takes over to create specialized versions. Supervised fine-tuning produces an instruction-following variant, while a separate reasoning pathway applies chain-of-thought training combined with reinforcement optimization. This dual approach resulted in a reasoning-focused 14B model that Mistral claims can match or beat similarly sized competitors—all while using less training data and compute resources.
Why Smaller Efficient Models Matter for AI Deployment
This development carries weight beyond just technical benchmarks. When advanced AI models can deliver strong performance with fewer resources, they become viable in environments that previously couldn't support them—think edge devices, smaller cloud instances, or on-premise servers with limited capacity.
More efficient models could reshape how companies integrate AI into their products and services. Instead of requiring expensive infrastructure, businesses might deploy capable language models on standard hardware, opening doors for startups and organizations with tighter budgets.
The Ministral 3 release signals a broader industry trend toward efficiency without sacrifice. As distillation techniques improve, the gap between massive flagship models and their smaller counterparts continues to narrow, potentially democratizing access to cutting-edge AI capabilities.
 Victoria Bazir
Victoria Bazir


