 Eseandre Mordi
Eseandre Mordi

Alibaba, working alongside Tsinghua LeapLab, has unveiled HopChain, a multi-hop data synthesis framework built to sharpen vision-language model reasoning. The system targets reinforcement learning with visual reasoning (RLVR) and fits into a broader wave where AI models now complete complex tasks in record time, compressing timelines that once seemed out of reach.
How HopChain's Dependency-Linked Design Fixes Broken Reasoning Chains
The core problem with standard training data is that it rarely maintains a continuous reasoning thread grounded in visual evidence. When a model loses that thread mid-problem, errors pile up fast.
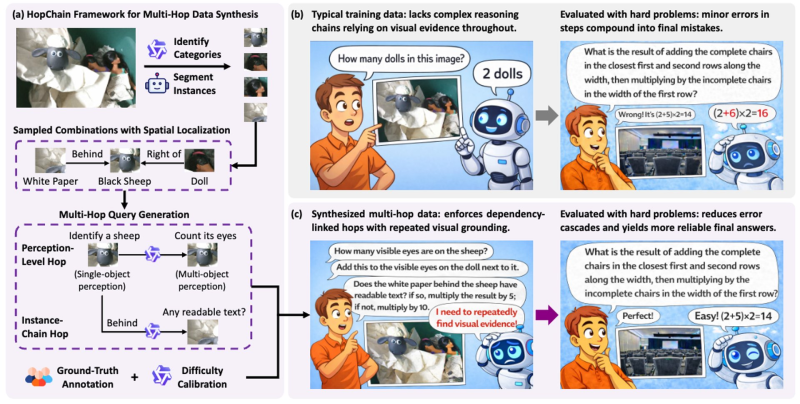
HopChain solves this by generating structured training data where each reasoning step explicitly links back to visual elements from the previous one. Models trained this way are forced to keep re-referencing what they actually see, rather than drifting into plausible-sounding guesses.
Qwen3.5 Gains 50+ Points on Ultra-Long Chain-of-Thought Benchmarks
The results are hard to ignore. After training with HopChain data, Qwen3.5 jumped more than 50 points on ultra-long chain-of-thought benchmarks. The model is now taking on DeepSeek-V3 in the leaderboard race, reflecting how competitive the multimodal space has become.
What makes this notable is the method. Rather than chasing gains through scale alone, HopChain bets on better training data architecture. The framework reduces error cascades and produces more consistent answers in long reasoning chains. It also fits a wider pattern of high-stakes experimentation at Alibaba, where the Rome agent triggered security alarms across 1M training runs, showing how hard the lab is pushing its systems.
 Eseandre Mordi
Eseandre Mordi


