 Saad Ullah
Saad Ullah

⬤ The latest ArtificialAnalysis Intelligence Index puts Qwen3.5-27B in direct competition with DeepSeek-V3.2 and MiniMax-M2.5. The index pulls together results from 10 evaluations, including GDPval-AA, SciCode, AA-Omniscience, and Humanity's Last Exam, comparing a total of 410 models. Watching a 27B model go toe-to-toe with bigger, more established systems marks a real shift in how we think about model performance.
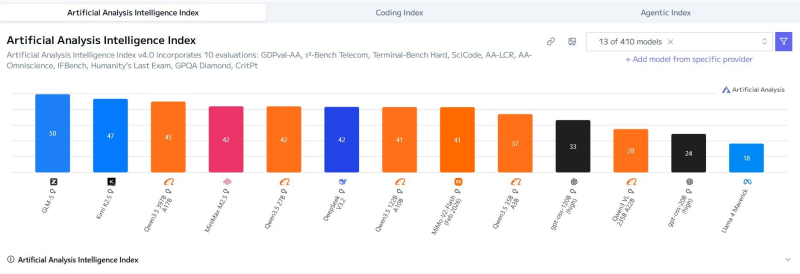
⬤ On the leaderboard, Qwen3.5-27B scores in the mid-40s, sitting right alongside MiniMax-M2.5 and close behind DeepSeek-V3.2. GLM-4.5 leads the pack with a score of 50, followed by Kimi-K2.5 in the high-40s. The tight clustering between the low-40s and high-40s across multiple models tells a clear story: architectural differences matter less than they used to when it comes to raw benchmark results.
⬤ That preference for dense over MoE architectures sits at the heart of what makes Qwen3.5-27B's showing notable. Compact dense models have long been seen as underdogs compared to sprawling MoE systems, but this leaderboard entry suggests that gap is narrowing fast. Efficiency and architectural discipline are increasingly competitive advantages on their own.
⬤ The positioning of Qwen3.5-27B, DeepSeek-V3.2, and MiniMax-M2.5 within just a few points of each other on a 410-model leaderboard signals a broader shift in AI development. The conversation around model design is moving away from "bigger is better" and toward smarter, leaner systems that can punch well above their weight.
 Saad Ullah
Saad Ullah


