 Peter Smith
Peter Smith

⬤ BIGAI dropped its Native Parallel Reasoner on Hugging Face, pushing large language model performance forward in a big way. The framework uses a teacher-free training method that lets models develop real parallel reasoning skills without outside expert guidance. It's built to improve both accuracy and speed on tough reasoning tasks, making it a solid infrastructure upgrade for AI development.
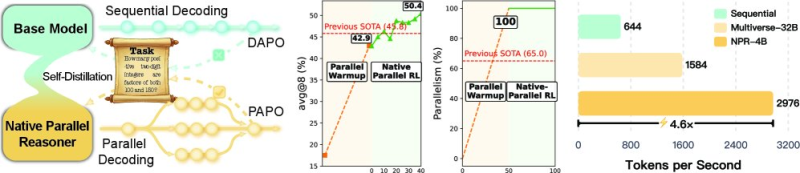
⬤ The Native Parallel Reasoner delivered a 24.5% performance gain over previous baselines. Benchmark results show model accuracy climbing from around 42.9% to 50.4%, beating earlier top results. BIGAI also hit 100% parallelism through the Native-Parallel RL phase, making a complete switch from traditional sequential decoding to fully parallel reasoning.
⬤ Speed gains are equally impressive. BIGAI's NPR-4B model generates 2,976 tokens per second—4.6× faster than before. That's a major jump from 1,584 t/s for multiverse-based methods and 644 t/s for sequential decoding. These improvements cut down inference delays and make deploying medium and large language models much more practical.
⬤ The Native Parallel Reasoner launch reflects a wider shift in AI toward designs that prioritize speed, scalability, and efficiency. By delivering better accuracy and much faster throughput without needing proportionally more resources, BIGAI's framework strengthens the case for parallel-first model architecture and could shape how future AI systems get built and optimized.
 Peter Smith
Peter Smith


