 Saad Ullah
Saad Ullah

⬤ A team from Beihang University, Shanghai AI Lab, and Zhejiang University just unveiled a spatial reasoning framework that tackles a major weakness in vision-language models. Their Geometrically-Constrained Agent (GCA) zeros in on the semantic-geometric gap—that tricky space where visual information gets lost when converted to text. The key innovation? Making AI systems lock down strict geometric constraints before they even try solving spatial problems.
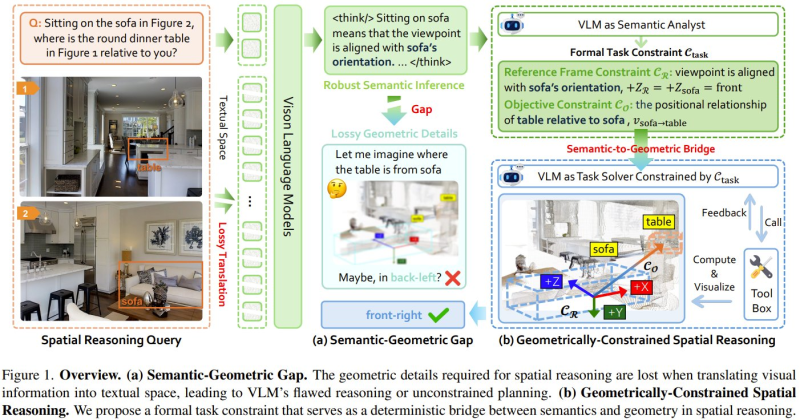
⬤ The accompanying image shows exactly where traditional vision-language models fall short. When asked about a table's position relative to a sofa, the model fumbles because there's no clear spatial reference frame. Without explicit geometric structure, even semantically "correct" interpretations can lead straight to wrong answers.
⬤ GCA fixes this by breaking the reasoning process into distinct phases. First, it establishes formal geometric rules—defining reference frames, spatial constraints, and how objects relate to each other. Only then does it move forward with actually solving the task. The results speak for themselves: 27% performance improvement on spatial reasoning benchmarks compared to previous top methods.
⬤ This matters beyond just better test scores. Spatial reasoning sits at the foundation of real-world AI applications—from robots navigating physical spaces to AI agents understanding their environments. By tightening the connection between what AI "sees" semantically and what exists geometrically, GCA points toward more reliable AI systems that can actually function in the physical world. The takeaway? Adding formal geometric structure might be the missing piece for AI that truly understands space.
 Saad Ullah
Saad Ullah


