 Marina Lyubimova
Marina Lyubimova

⬤ Alphabet's Google DeepMind officially launched Gemini 3.1 Flash-Lite, positioning it as the most cost-efficient model in the Gemini 3 series. The release brings adjustable "thinking levels" that let developers dial in reasoning depth for tasks like building UIs, generating dashboards, or running complex simulations. According to reporting on Gemini 3.1 Pro throughput drops 46% to 50 TPS on Google Vertex, throughput variability remains a critical watch point across the Gemini family.
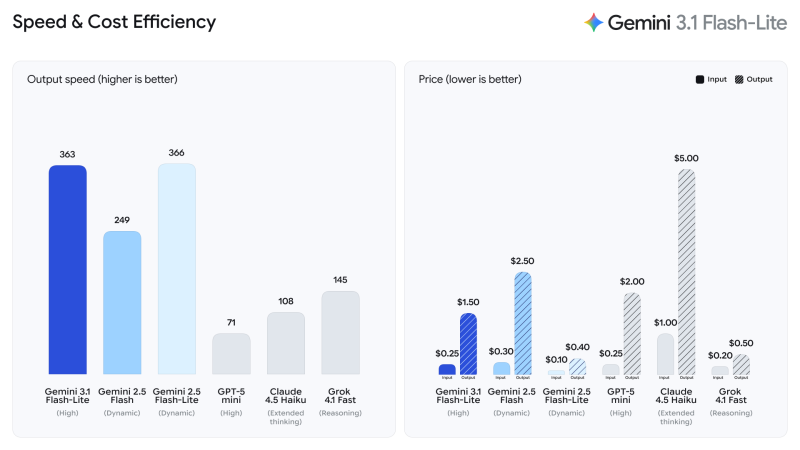
⬤ Speed-wise, the model posts 363 tokens per second, overtaking Gemini 2.5 Flash at 249 TPS and nearly matching Gemini 2.5 Flash-Lite at 366 TPS. Competing models fall well behind: GPT-5 mini logs 71 TPS, Claude 4.5 Haiku 108, and Grok 4.1 Fast 145. As highlighted in Coderabbit beats Gemini in new 51.30 F1 score code review test, raw throughput does not always guarantee benchmark wins.
Gemini 3.1 Flash-Lite offers the most cost-effective balance between speed and price in the entire Gemini 3 series.
⬤ On pricing, Flash-Lite comes in at $0.25 input / $1.50 output per million tokens, undercutting Gemini 2.5 Flash ($0.30 / $2.50), GPT-5 mini (roughly $2.00 output), and Claude 4.5 Haiku ($1.00 / $5.00) by a wide margin. In parallel, Google's Gemini 3.1 Pro powers 1 million token workflows with NotebookLM, revealing how Google is pushing on both scale and cost at the same time.
⬤ The launch reflects just how much pricing pressure has become a deciding factor in enterprise AI adoption. With throughput, cost, and long-context capability all converging as buyer priorities, Gemini 3.1 Flash-Lite strengthens Google's competitive position in cloud infrastructure and solidifies the case for GOOGL across AI-driven workloads.
 Marina Lyubimova
Marina Lyubimova


