 Peter Smith
Peter Smith

⬤ Cognition just dropped an early preview of its SWE-1.6 model, and it's showing some serious gains over the previous version. This new model was trained with massively scaled compute and a refined reinforcement learning recipe. The result? SWE-1.6 now beats several top open source models on the tough SWE-Bench Pro benchmark. We're talking about 731 agentic coding tasks spread across 41 repositories, where SWE-1.6 hits 51.7% - a solid jump from SWE-1.5's 40.1%.
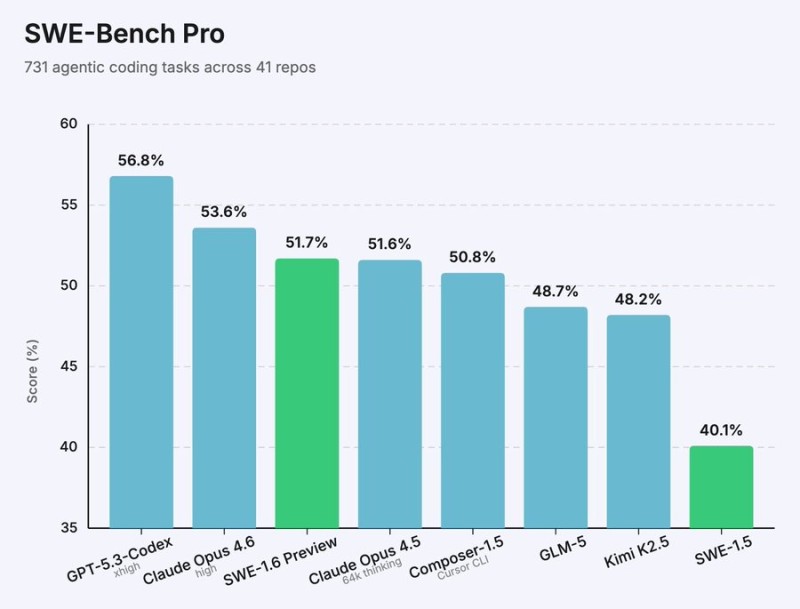
⬤ When you stack it up against the competition, SWE-1.6 holds its own pretty well. GPT-5.3-Codex still leads the pack at 56.8%, with Claude Opus 4.6 right behind at 53.6%. But SWE-1.6 edges past Composer-1.5, GLM-5, and Kimi K2.5. What's really interesting is how Cognition pulled this off - their training stack now runs 6x faster than it did just three months ago, even though they're throwing 100x more compute at the problem. And they're still cranking out around 950 tokens per second during inference. That's the sweet spot: deeper reasoning without sacrificing speed.
⬤ This release fits into a bigger picture of rapid progress in AI coding models. Earlier this year, Mistral AI Releases Mistral Vibe 2.0 With Expanded SWE Agent Features pushed agent capabilities forward. Meanwhile, Minimax Releases M25 OpenSource Model With 80.2 SWEBench Score, showing that open source options are catching up fast.
⬤ Why does SWE-1.6 matter? Breaking past 50% on SWE-Bench Pro isn't just a number - it's a real benchmark for how well these models handle actual coding challenges. As these benchmarks become the standard for measuring AI reasoning quality, releases like SWE-1.6 help us see where open source stands against proprietary models and where the field is heading next.
 Peter Smith
Peter Smith


