 Usman Salis
Usman Salis

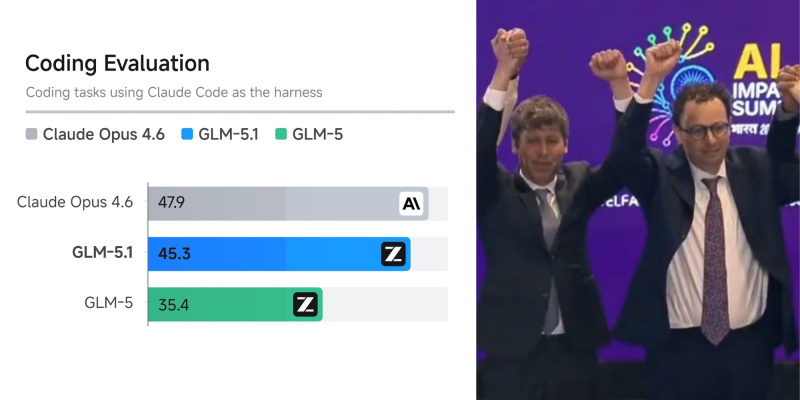
A new coding benchmark highlights intensifying competition between open and proprietary AI models. As X Freeze reported, GLM-5.1 delivers coding performance close to Claude Opus 4.6, based on evaluations using Claude Code as the testing harness. The results show Claude Opus 4.6 scoring 47.9, while GLM-5.1 follows at 45.3, with GLM-5 at 35.4 - a gap that has narrowed considerably in a short development cycle.
How GLM-5.1 Benchmark Scores Compare to Claude Opus 4.6
The benchmark results align with broader industry data showing that while Claude Opus 4.6 still leads on several coding benchmarks, the margin is increasingly limited.
Independent comparisons indicate that proprietary models continue to outperform in some structured evaluations, but open models are approaching parity in practical coding scenarios.
The performance gap between open and proprietary models is narrowing faster than most expected, with GLM-5.1 reaching 45.3 against Claude Opus 4.6's 47.9 in real-world coding tasks.
This shift reflects rapid iteration cycles in open-source ecosystems, where frequent updates drive consistent improvements in performance and usability - also seen in GLM-5 outperforming GPT-5.1 Codex on LiveBench.
Cost efficiency remains a key differentiator in the comparison. GLM models offer significantly lower pricing while maintaining competitive performance, with some estimates showing several-fold cost advantages over Claude Opus models. This dynamic is accelerating adoption among developers seeking scalable solutions. At the same time, Anthropic's models continue to lead in complex reasoning and large-scale coding tasks - as reflected in Claude Opus 4.6 solving complex math problems, reinforcing their position at the high-performance end of the market.
Why Coding AI Competition Is Shifting Beyond Raw Benchmark Scores
Open-source alternatives are improving at a pace that is redefining what competitive AI infrastructure looks like for developers in 2025.
The evolving landscape highlights a broader shift in AI development, where performance parity is emerging alongside divergence in cost and deployment models. As open-source alternatives improve and enterprise adoption expands, competition is increasingly defined by efficiency and accessibility rather than raw benchmark dominance. This trend aligns with ongoing changes in digital ecosystems, including GOOGL's SEO shift toward AI-driven discovery, signaling a transition toward more distributed and competitive AI infrastructure.
Efficiency and accessibility are becoming the real battleground in AI development, with cost-competitive open models challenging the dominance of proprietary systems across enterprise deployments.
 Usman Salis
Usman Salis


