 Eseandre Mordi
Eseandre Mordi

Baidu's latest research may quietly redefine how multimodal AI learns to understand physical space. As reported by DailyPapers, researchers from Baidu and Huazhong University have introduced VEGA-3D, a framework that enables large language models to grasp 3D environments without relying on explicit geometric supervision - a persistent bottleneck in spatial AI development. The approach taps into something already available: the structural knowledge encoded inside video generation systems.
How VEGA-3D Extracts 3D Knowledge From Video Diffusion Models
Rather than building costly 3D pipelines, VEGA-3D repurposes video diffusion models as what the researchers describe as a "latent world simulator." These models, trained to produce temporally consistent video, inherently learn spatial and structural relationships between objects.
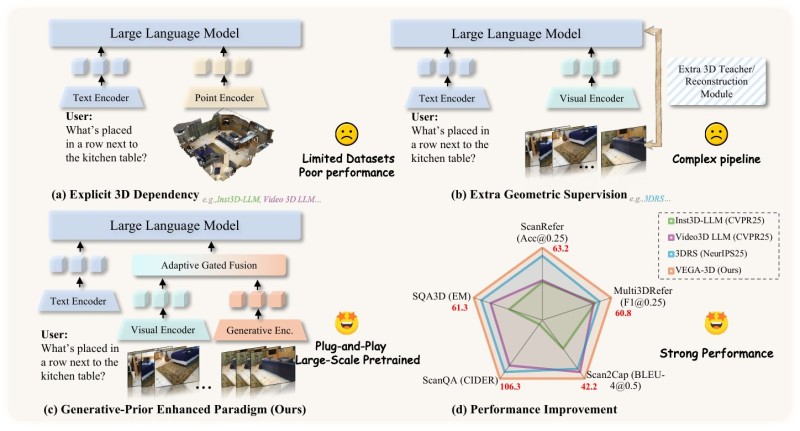
VEGA-3D extracts these geometric priors and injects them into multimodal systems via adaptive gated fusion - a mechanism that coordinates input across text, visual, and generative encoders. The result is a plug-and-play architecture that adds spatial awareness without requiring additional 3D datasets.
Benchmark Results: VEGA-3D Outperforms Inst3D-LLM, Video3D LLM, and 3DRS
The performance data is notable. VEGA-3D outperforms competing models - including Inst3D-LLM, Video3D LLM, and 3DRS - across four major benchmarks: ScanRefer, Multi3DRefer, Scan2Cap, and SQA3D. The gains reflect what happens when generative priors replace supervised geometric data as the foundation for spatial understanding. The architecture also reduces pipeline complexity, which matters for practical deployment.
This release fits a broader pattern in AI research: generative models trained for content creation are increasingly being repurposed for reasoning tasks. For Baidu, VEGA-3D builds on an expanding multimodal strategy also visible in ERNIE 5.0. For the field, it signals that spatial reasoning in AI systems may be closer than previously assumed - provided the right architectural choices are made. As AI systems become more capable of understanding physical environments, frameworks like VEGA-3D could become foundational to real-world interaction and robotics applications.
 Eseandre Mordi
Eseandre Mordi


