 Peter Smith
Peter Smith

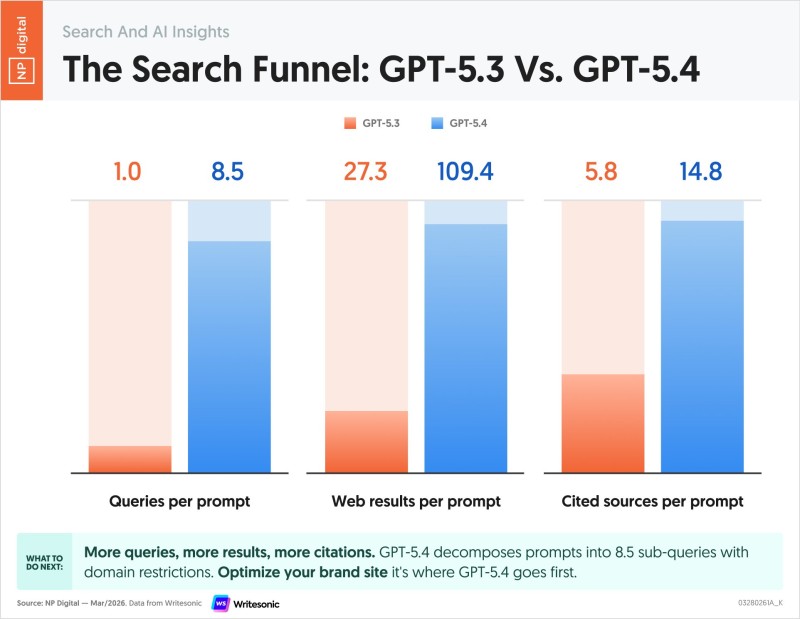
New research from Writesonic tracking AI search behavior shows that GPT-5.4 now runs an average of 8.5 queries per prompt, compared to just 1 query under GPT-5.3 - a clear sign that multi-step query decomposition is becoming the new standard. Digital marketing expert Neil Patel highlighted the findings, noting that the gap between model generations goes far beyond raw performance numbers.
The data shows a move toward multi-step query decomposition, with GPT-5.4 generating around 109.4 web results per prompt versus 27.3 for GPT-5.3.
The shift is visible across every metric in the dataset. Web results per prompt jumped from 27.3 to 109.4, while cited sources increased from 5.8 to 14.8. Rather than pulling from a single query, the model now builds responses from a broader base of layered inputs - producing outputs that are more structured and better referenced. You can see similar dynamics playing out in the broader model race covered in OpenAI GPT-5.4 Mini Hits 72.1% on OSWorld, Outpaces Rivals in 2025 Benchmark Race.
GPT-5.4 Prioritizes Brand Websites as Primary AI Search Sources
One of the more strategic findings in the data is where GPT-5.4 goes for information. The model shows a clear tendency to prioritize brand websites as primary sources - meaning content hosted on a company's own domain now carries more weight in shaping what AI surfaces in its responses. This is a notable departure from earlier behavior in GPT-5.3 and has real implications for how companies should think about first-party content.
Brand websites are emerging as primary sources in GPT-5.4 responses, which changes how first-party content influences AI-driven search outcomes.
For publishers and content teams, this is worth taking seriously. If AI models are increasingly drawing from owned channels, the quality and structure of on-site content becomes more important than ever for visibility across AI-driven platforms. Related context on model performance gaps is worth reviewing in GPT-5 Shadow API Study Reveals 47% Performance Gaps in AI Services.
How GPT-5.4's Multi-Query Retrieval Compares to GPT-5.3
The numbers tell a clean story:
- Average queries per prompt: 1 (GPT-5.3) vs. 8.5 (GPT-5.4)
- Web results per prompt: 27.3 (GPT-5.3) vs. 109.4 (GPT-5.4)
- Cited sources per prompt: 5.8 (GPT-5.3) vs. 14.8 (GPT-5.4)
The increasing number of queries, results, and citations points to a more layered approach to information discovery - one that could reshape how digital content gets consumed across AI platforms.
This evolution toward deeper, multi-query retrieval reflects a broader pattern in how leading models are being developed. The mechanics behind it - and what it means for reasoning quality - are explored further in OpenAI Rolls Out GPT-5.4 Thinking with 92.8% on GPQA Diamond.
 Peter Smith
Peter Smith


