 Marina Lyubimova
Marina Lyubimova

⬤ Researchers from Fudan University and National University of Singapore launched FutureOmni, a benchmark testing whether AI can predict what happens next using visual and auditory information together. The benchmark moves away from describing past or present content and instead challenges models to reason forward using multi-modal cues.
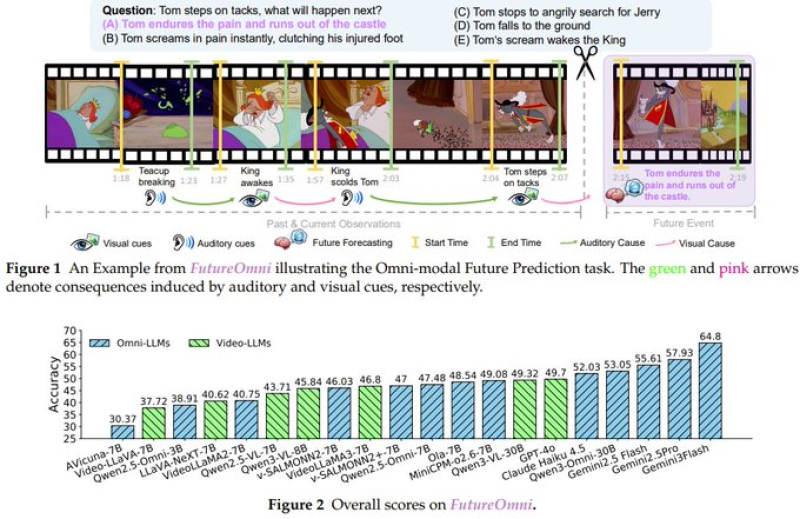
⬤ FutureOmni structures tasks through sequences of video frames and sound signals, pushing models to infer likely outcomes instead of recognizing existing patterns. Models must determine what happens next by combining visual actions with audio triggers, like sound cues that precede events. This design emphasizes causal and temporal reasoning, making it tougher than standard video understanding or captioning benchmarks.
⬤ Current multimodal models show clear performance limits. The best systems hit just 64.8% accuracy, with many scoring significantly lower. "The ability to anticipate future events is critical for more advanced applications," researchers noted. Both omni-modal large language models and video-focused language models struggle with future prediction. Strong performance in recognizing or summarizing audio-visual inputs doesn't automatically mean reliable forecasting ability.

⬤ Predictive reasoning remains a weak point in today's multimodal systems. The benchmark establishes a standardized framework for measuring progress and shows that targeted training strategies can improve performance on future prediction and general reasoning tasks. Better performance here could shape developments in robotics, autonomous systems, and real-world decision-making tools where understanding what happens next matters most.
 Marina Lyubimova
Marina Lyubimova


