 Saad Ullah
Saad Ullah

⬤ Researchers have introduced LMEB (Long-horizon Memory Embedding Benchmark), a framework built to evaluate how well AI embedding models handle long-term memory across complex, extended interactions. Unlike traditional retrieval benchmarks focused on short passages, LMEB tests memory behavior over time, spanning 22 datasets and 193 tasks designed to stress-test the four core memory types used in modern AI systems.
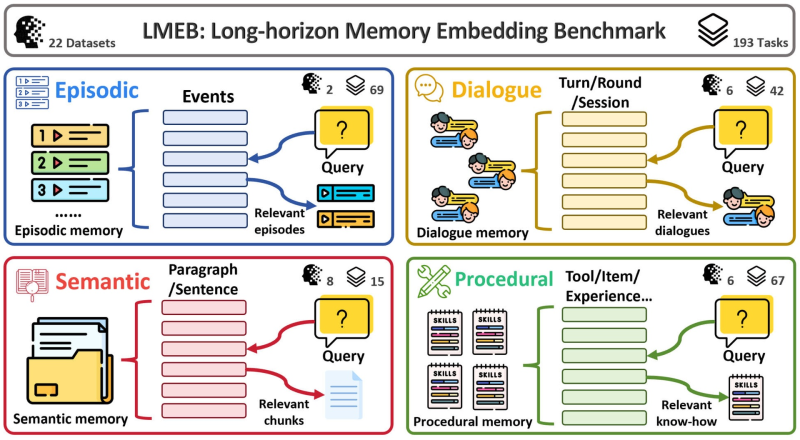
⬤ The benchmark covers episodic, dialogue, semantic, and procedural memory. Episodic tasks check whether a model can reconstruct sequences of past events from stored interaction histories. Dialogue memory focuses on surfacing the most relevant exchanges within multi-turn conversation sessions. Semantic tasks require retrieving accurate information from document collections, while procedural tasks test whether a model recalls tools, skills, or prior operational knowledge when responding to new queries. This mirrors the breadth of memory demands seen in Huawei's CLIGym, a 1,655-task AI training framework built around agent-oriented workflows.
⬤ One of LMEB's key findings is that model size is not a reliable predictor of memory performance. Across long-horizon retrieval scenarios, smaller models sometimes matched or outperformed larger ones, echoing results seen in compact architectures like Nanbeige-4B, which scored 87.4 on reasoning benchmarks while beating 32B-scale systems. This challenges the assumption that scaling embeddings always translates to better contextual recall.
⬤ LMEB arrives as AI agents, assistants, and enterprise knowledge tools take on longer, more complex tasks spanning multiple sessions and document sets. Maintaining coherent context across all those interactions is no longer optional. Related work on retrieval verification has already shown that targeted tool verification can improve accuracy on hard math benchmarks by 31.6% for models like Qwen and Llama, pointing to a broader industry push to make AI memory and reasoning more reliable at scale.
 Saad Ullah
Saad Ullah


