 Sergey Diakov
Sergey Diakov

⬤ NVIDIA solidified its dominance in AI hardware as new benchmark data revealed a massive performance and cost edge across inference metrics. Latest Artificial Analysis Hardware Benchmarking results show NVIDIA H100 and B200 systems hitting the lowest Cost Per Million Input and Output Tokens at Reference Speed when running Llama 3.3 70B at 30 tokens per second. The H100 clocked in at just 1.06 dollars per million tokens, crushing AMD's MI300X at 2.24 dollars and leaving Google's TPU v6e in the dust at 5.13 dollars.
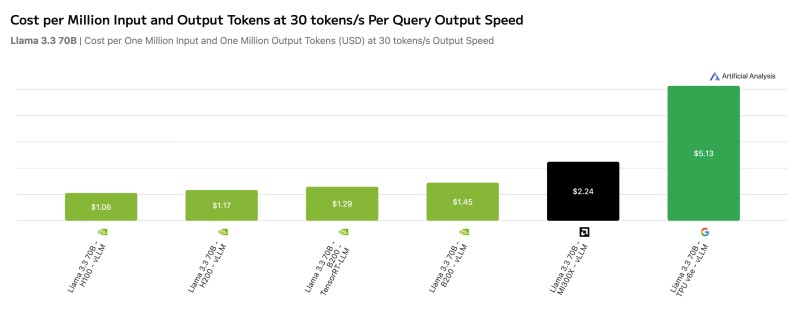
⬤ The cost metric divides rental pricing by sustained throughput at 30 output tokens per second per query, creating a standardized way to compare system efficiency. Multiple NVIDIA configurations landed between 1.06 and 1.45 dollars, with both Hopper and Blackwell generation chips outpacing competitors. TPU v6e, despite a lower 2.70 dollar hourly chip cost, posted the highest token cost due to weaker throughput at the tested speed. AMD MI300X settled in the middle at 2.24 dollars. These numbers come from the System Load Test, which measures inference throughput across different concurrency levels using cloud rental pricing data.
⬤ TPU v6e results are currently limited to Llama 3.3 70B due to vLLM support constraints, while NVIDIA and AMD systems were tested across additional models including DeepSeek R1, Llama 4 Maverick and gpt-oss-120b. Next-generation accelerators like Google's TPU v7 and AMD's MI355X aren't widely available yet, so the comparison focuses on hardware accessible for cloud deployment today. TPU v7 is expected to bring major improvements in compute, memory and bandwidth, but its cost-efficiency impact won't be clear until pricing drops.
⬤ The widening gap in token-level operating costs matters as AI infrastructure spending continues shaping sentiment across semiconductor and cloud sectors. NVIDIA's leadership in tokens-per-dollar efficiency cements its position for high-volume inference workloads, while upcoming releases from AMD and Google create uncertainty about future performance gaps. Cost-per-token metrics are becoming the key factor in evaluating hardware demand and competitive positioning in AI computing.
 Sergey Diakov
Sergey Diakov


