 Alex Dudov
Alex Dudov

⬤ Here's the thing - researchers just dropped a game-changing approach called Recursive Language Models (RLMs) that completely flips how LLMs deal with long documents. Instead of cramming everything into one giant prompt and watching the model struggle, this technique treats your input like a Python variable. The system can inspect it, slice it up, and analyze specific chunks on demand - basically turning your 10 million token document into something the model can actually navigate intelligently.
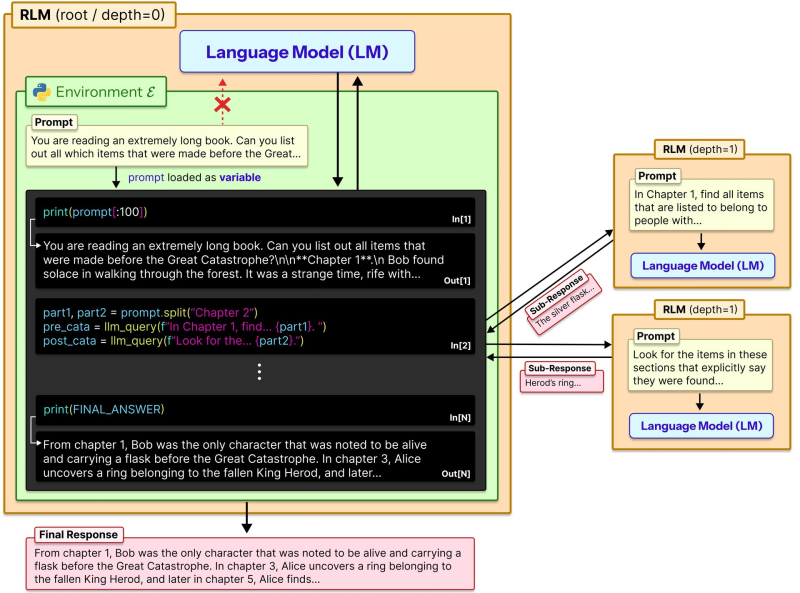
⬤ The way this works is pretty clever. A root language model gets your initial question and starts writing code to explore different parts of your massive text file. It splits content into manageable sections, pulls only the relevant bits it needs, and here's where it gets recursive - it can call itself on those specific segments. Each piece gets processed independently, then everything gets stitched back together into your final answer. No more losing track of what was mentioned 50,000 tokens ago.
⬤ The results are absolutely crushing it - we're talking 10 million tokens or more without the usual context degradation that tanks performance. Instead of chopping off important details or forcing everything into weak summaries, the model dynamically grabs exactly what it needs from storage. By writing and running code to navigate the input, RLMs keep full access to every detail while maintaining stable, structured inference throughout.

⬤ What makes this approach fundamentally different is how it reimagines context itself. Traditional models treat text as a static wall of words you throw at them. Recursive Language Models treat it as a searchable database they can decompose and explore. This means comparing sections from opposite ends of a document, recovering specific facts after summarization, and handling long-horizon reasoning tasks that would make standard prompt-based systems completely fall apart.
 Alex Dudov
Alex Dudov


