 Artem Voloskovets
Artem Voloskovets

Perplexity just dropped two new embedding model families that are quietly making a big splash in the AI infrastructure world. Called pplx-embed-v1 and pplx-embed-context-v1, they're built for one thing: retrieving information from the web at massive scale - fast, efficiently, and without breaking your storage budget.
The flagship 4B model doesn't just compete with the likes of Gemini and Qwen - it outperforms them on major benchmarks. And with storage efficiency up to 32 times higher using the binary variant, it's not just a marginal improvement. It's a different category entirely. To prove the point at scale, Perplexity ran internal benchmarks using 115,000 real-world queries - not synthetic tests, but the kind of messy, unpredictable traffic the open web actually throws at you.
4B Model Tops MTEB Multilingual v2 With Up to 32x Storage Savings
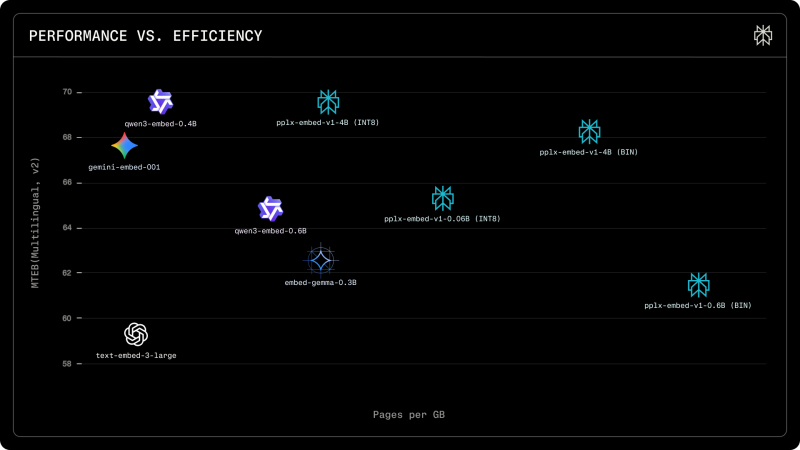
On the MTEB Multilingual v2 benchmark - the go-to standard for evaluating multilingual retrieval - the pplx-embed-v1-4B (INT8) scores above 69, pushing past gemini-embed-001 and qwen3-embed-0.4B. But what really sets it apart is what happens when you flip to the binary variant. The pplx-embed-v1-4B (BIN) holds its benchmark performance while shooting far ahead on the efficiency axis - storing up to four times more pages per gigabyte than competitors, and up to 32 times more in binary format. That's the kind of number that matters when you're operating at web scale.
The models are fully open-source under an MIT license on Hugging Face, continuing Perplexity's push into AI infrastructure and retrieval optimization.
Smaller variants like pplx-embed-v1-0.6B round out the lineup with solid performance-to-storage trade-offs, making the family accessible for teams that don't need the full horsepower of the 4B. Meanwhile, Perplexity's broader AI ambitions keep expanding - from upgrading Deep Research with Anthropic's OPUS-4 to assembling a Model Council featuring 3 leading AI systems.
Open-Source MIT License Puts These Models in Everyone's Hands
Both model families are available right now on Hugging Face under an MIT license - meaning any developer, startup, or research team can pull them down and start experimenting. This move fits squarely into Perplexity's strategy of building credibility in AI infrastructure, not just consumer search. The company has already proven it can compete with Google and OpenAI on benchmarks, and now it's making a direct play for the retrieval and embedding layer that powers modern AI applications. If the benchmark numbers hold up in production, pplx-embed-v1 could become a serious default for teams building RAG pipelines, semantic search, and large-scale document retrieval systems.
 Artem Voloskovets
Artem Voloskovets


