 Usman Salis
Usman Salis

A research team led by Shaobo Wang has introduced OPUS, a new framework for data selection in large language model pre-training. The method dynamically selects the most impactful data during every training iteration, aiming to improve both efficiency and overall model quality. As reported by 机器之心 JIQIZHIXIN, the approach marks a meaningful step forward in how training pipelines handle data prioritization.
OPUS focuses on continuously optimizing data selection instead of relying on static datasets. The framework updates its selection process throughout training, allowing models to prioritize higher-impact data as learning progresses. This approach contrasts with conventional static methods that do not adapt during training.
How OPUS Outperforms Static and Dynamic LLM Baselines
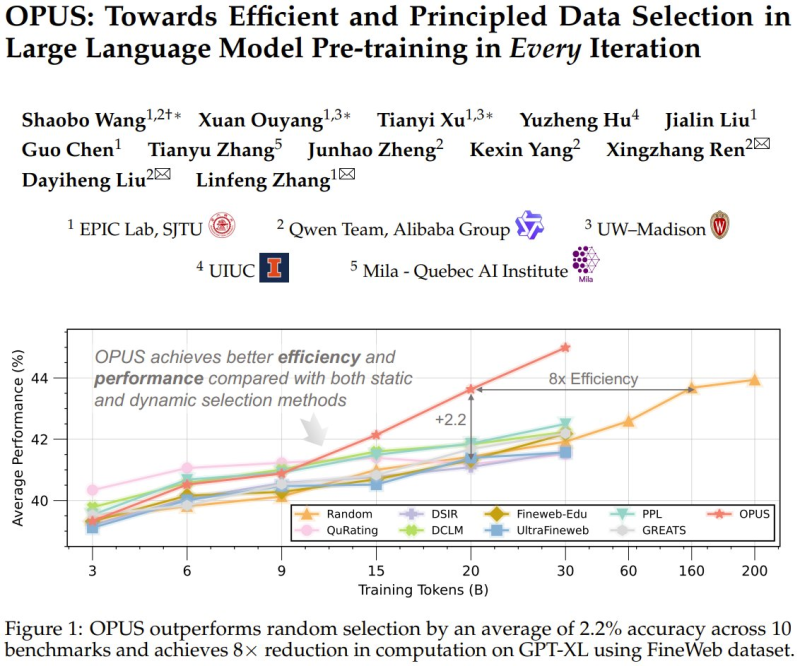
According to the research results, OPUS outperforms both static and dynamic baseline methods across multiple benchmarks. The model achieves an average improvement of about 2.2% in accuracy across 10 benchmarks and reduces computation requirements by up to 8x in GPT-XL training using the FineWeb dataset.
The shift toward more adaptive systems reflects broader industry discussions around Claude AI breakthrough raises new LLM security risks.
The framework updates its data selection process throughout training, allowing models to continuously prioritize higher-impact inputs as learning progresses.
These gains highlight improvements in both efficiency and performance, aligning with trends observed in GPT models drop up to 9% in AI trading tests.
OPUS and the Future of LLM Data Efficiency
The introduction of OPUS reflects a broader shift in AI development toward improving data efficiency as scaling raw data becomes more challenging. Research indicates that the field is moving from simply increasing data volume to optimizing data quality and selection during training.
As raw data scaling hits diminishing returns, continuous data optimization during training may become a defining factor in next-generation LLM development.
Methods like OPUS highlight how continuous data optimization may shape future LLM development and training strategies. The results suggest that smarter data selection - rather than larger datasets - could become the primary lever for advancing model performance.
Key Findings From the OPUS Research
- Average accuracy improvement of 2.2% across 10 benchmarks
- Up to 8x reduction in computation requirements for GPT-XL training
- Evaluated on the FineWeb dataset
- Outperforms both static and dynamic baseline methods
- Dynamically updates data selection at every training iteration
OPUS demonstrates that adaptive data selection during pre-training can substantially reduce computational costs without sacrificing - and in fact improving - model accuracy.
The framework positions dynamic data optimization as a scalable path forward, particularly relevant as the industry faces growing constraints around data quality and training efficiency at scale.
 Usman Salis
Usman Salis


