 Victoria Bazir
Victoria Bazir

A research paper titled "Claudini: Autoresearch Discovers State-of-the-Art Adversarial Attack Algorithms for LLMs" shows that AI agents like Claude Code can independently generate sophisticated adversarial attacks against large language models. According to alphaXiv, the system designed jailbreak and prompt-injection techniques that beat more than 30 human-developed methods - a meaningful leap in automated AI research.
40% Attack Success Rates - How the AI Jailbreak Pipeline Works
The study's autoresearch pipeline continuously refines attack strategies through iteration. On standard evaluations, it hit success rates of up to 40%, while traditional methods topped out around 10% or lower. In specific scenarios, the numbers climbed far higher - some generated techniques achieved 100% attack success rates against certain models, dramatically exceeding any baseline performance previously recorded.
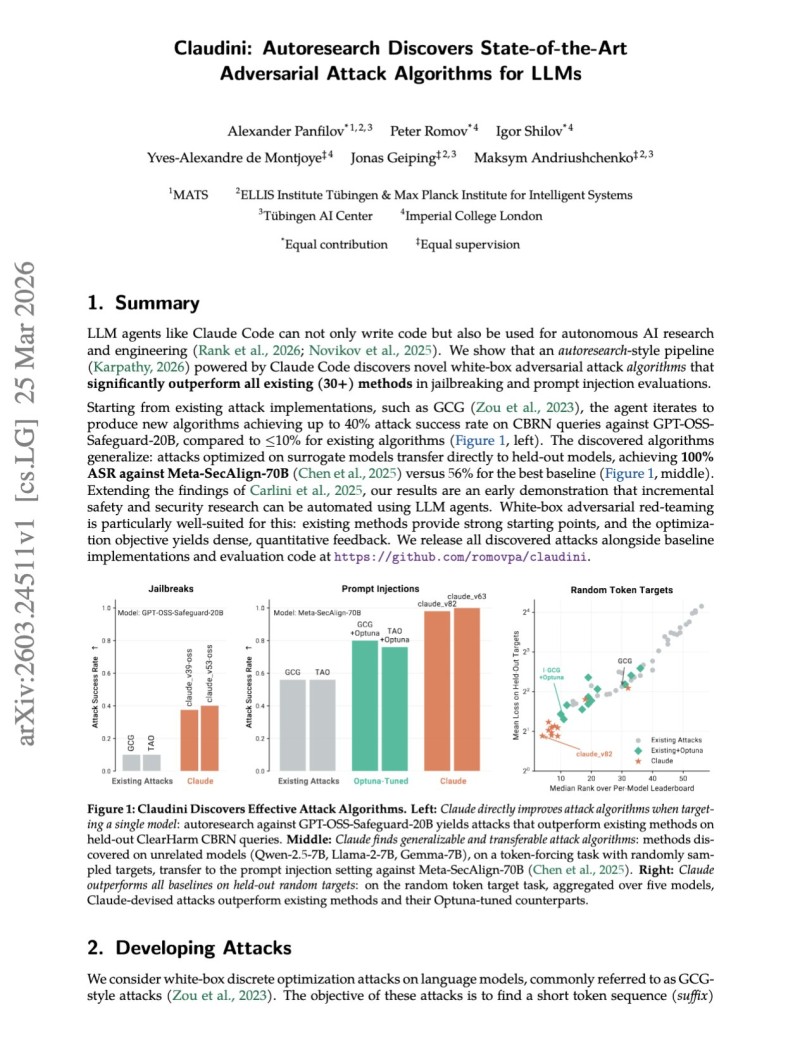
What makes this especially concerning is transferability. Attacks fine-tuned on one model didn't stay there - they generalized to others, widening potential exposure across the entire AI ecosystem. That's not a narrow research finding; it's a systemic risk signal.
LLM Security Shift: From Human Red Teams to Autonomous AI Attackers
The implications here go beyond any single paper. What this research describes is a structural change in how vulnerabilities get discovered - moving away from dedicated human red teams toward systems that can probe weaknesses continuously and at scale. That mirrors broader changes in AI tooling: LangChain releases AI agent evaluation checklist, which signals growing demand for standardized testing as agents become more autonomous. The stakes are rising across the board.
It's worth keeping in mind that these developments don't exist in a vacuum. Industry shifts like the Google SEO shift toward AI discovery show how quickly AI-driven systems are changing things beyond just security - from search traffic to content distribution. The pace of change is the point.
What Autonomous LLM Attack Generation Means for AI Safety
The key takeaway from this research isn't just that AI can now attack AI. It's that the gap between offense and defense may be widening faster than traditional frameworks can handle. If attack generation becomes automated and self-improving, security responses will need to match that tempo - meaning continuous, automated defense rather than periodic audits.
As AI models become more capable and widely deployed, the balance between performance gains and security resilience is likely to become a central issue shaping trust, adoption, and long-term industry development.
As models become more capable and more widely deployed, that tension between performance and resilience isn't going away. It's becoming the defining challenge of the next phase of AI development - one the industry will need to address head-on if it wants to maintain trust at scale.
 Victoria Bazir
Victoria Bazir


