 Eseandre Mordi
Eseandre Mordi

⬤ MiniMax has released MiniMax M2.7, a new frontier model with 200k context and a 56% SWE-Pro score, built around a self-evolving training process that runs over 100 internal optimization loops during reinforcement learning. This approach delivers roughly 30% internal performance gains without external intervention, making M2.7 a technically distinct entry in the current AI model race.
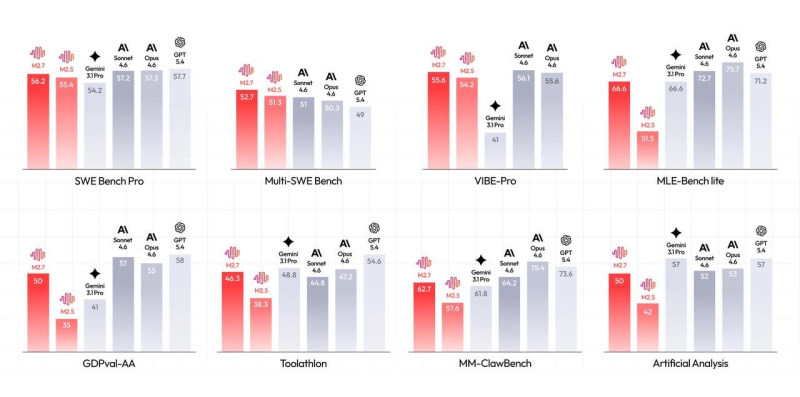
⬤ Benchmark results place M2.7 firmly in the top tier. On SWE Bench Pro it scored 56.2%, trailing Claude Opus 4.6 (57.3%) by just one point. The model also posted 55.6% on VIBE-Pro and 66.6% on MLE-Bench Lite, matching Gemini 3.1 Pro. Multi-SWE Bench (52.7%) and MM-ClawBench (62.7%) results confirm consistent execution across coding and machine learning research tasks.
MiniMax M2.7 is the first model to demonstrate genuine self-improvement through reinforcement learning at this scale.
⬤ Beyond raw scores, M2.7 targets real enterprise workflows. It handles multi-agent pipelines and complex outputs including reports, financial models, and presentations. On GDPval-AA it scored 50, while Toolathlon reached 46.3%, reflecting solid competence in structured, tool-based environments. MiniMax also launched OpenRoom, an open-source interactive agent environment that extends M2.7's utility for developers building agentic systems. Meanwhile, OpenAI's GPT-5.4 Mini hit 72.1% on OSWorld, outpacing rivals across 2025 benchmark rankings, raising the bar for the entire field.
⬤ The broader competitive picture is shifting fast. Gemini 3.1 Pro throughput dropped 46% to 50 tokens per second on Google Vertex, highlighting that raw capability gains can come at a real infrastructure cost. What MiniMax M2.7 signals is that training efficiency and agent-ready architecture, not just parameter scale, are now the defining battlegrounds in frontier AI.
 Eseandre Mordi
Eseandre Mordi


