 Usman Salis
Usman Salis

⬤ Microsoft researchers, working with CUHK Shenzhen, have rolled out a new training framework that helps AI models get better at reasoning with spoken language. Called TARS, this approach tackles a common weakness in speech-based large language models—they typically fall short on complex reasoning compared to models that work with text. The focus here is closing what's known as the "modality gap," the difference in how well AI handles speech versus written words.
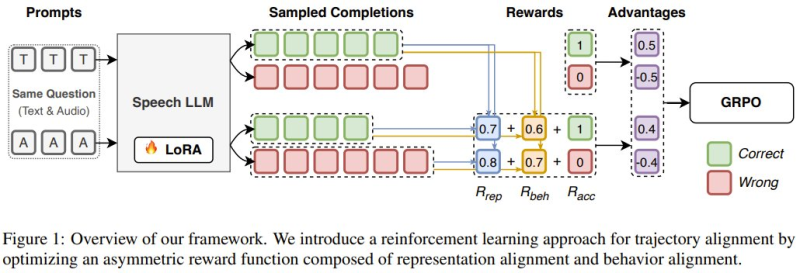
⬤ Speech models usually struggle with reasoning tasks because spoken input comes with more variability and background noise than clean, structured text. TARS addresses this by using two alignment signals during training. The first aligns how speech models process information internally with how text models do it. The second aligns their final outputs. This dual approach means the model learns to both think and respond more like its text-based counterparts.
⬤ The results are substantial. TARS achieves state-of-the-art performance among 7B-parameter speech language models on tough benchmarks like MMSU and OBQA. These aren't simple recognition tests—they measure multi-step reasoning and conceptual understanding, making the improvements particularly meaningful for real-world applications.

⬤ This matters because better speech reasoning means voice-based AI can handle more complex tasks reliably. For Microsoft, it strengthens their position in multimodal AI development and brings speech-driven interfaces closer to matching the capabilities of text-based systems. As TARS-like methods develop further, we're likely to see voice assistants and speech interfaces handling increasingly sophisticated reasoning tasks across everyday applications.
 Usman Salis
Usman Salis


