 Saad Ullah
Saad Ullah

⬤ Kimi K2.5 just hit a major benchmark in AI development by taking the top spot among open-source models in Code Arena's agentic coding tasks. The model scored 1447 points and landed at #5 overall, putting it right up there with some of the biggest proprietary AI systems in a test built to measure advanced coding skills and autonomous problem-solving.
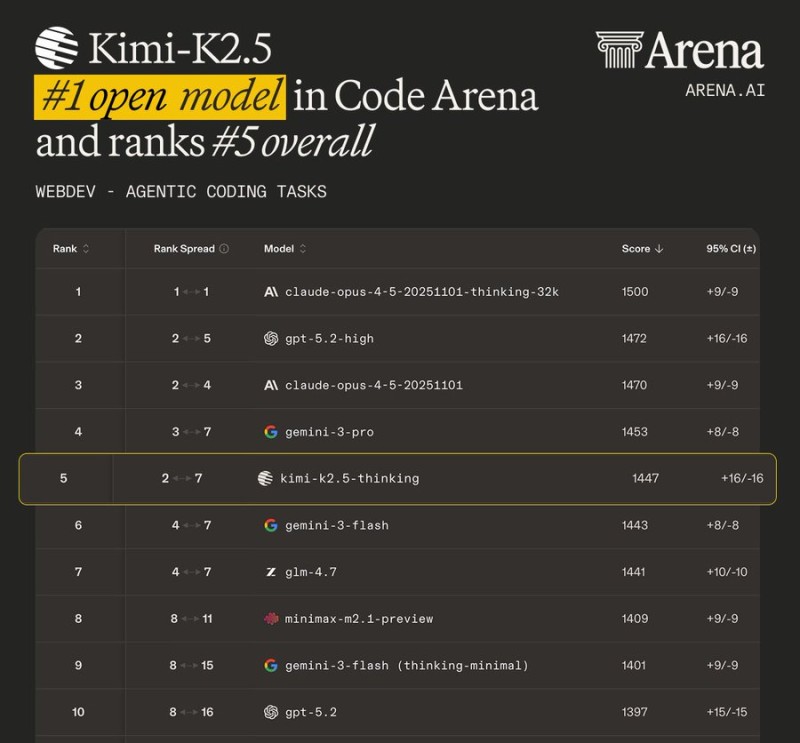
⬤ The Code Arena leaderboard shows Kimi K2.5 pulling ahead of other open and hybrid competitors like GLM-4.7. What's interesting is how close it sits to proprietary models such as Gemini 3 Flash—the confidence intervals actually overlap, suggesting they're performing at pretty similar levels. It's a clear sign that open-source models are catching up in these tough evaluation environments.
⬤ The benchmark zeroes in on agentic coding tasks, which test how well a model can plan out steps, reason through problems, and execute complex programming workflows. Doing well here means more than just spitting out code—it shows the model can handle structured problem-solving and make smart decisions. Kimi K2.5's performance suggests it can hold its own in scenarios that actually mirror real software development work.
⬤ This matters for the wider AI market because it shows open-source systems are reaching the same level as closed alternatives in demanding benchmarks. When open models like Kimi K2.5 can compete head-to-head in standardized tests like Code Arena, it could shift how companies think about adoption, development strategies, and whether to go with open or proprietary AI tools in software and tech industries.
 Saad Ullah
Saad Ullah


