 Usman Salis
Usman Salis

Cursor has quietly raised the stakes in AI-assisted development with a new coding model built on continued pretraining and scaled reinforcement learning. The release frames itself as a direct response to a market that's shifting its priorities: as AI coding tools multiply, raw benchmark scores are losing ground to a simpler question - how much does it actually cost to run this thing at scale?
61.3 on CursorBench: How Composer 2 Stacks Up Against GPT-5.4 and Opus 4.6
The numbers are hard to ignore. Composer 2 scores 61.3 on CursorBench and 61.7 on Terminal-Bench 2.0, a clear step up from Composer 1.5 and within competitive range of models that cost significantly more to run.
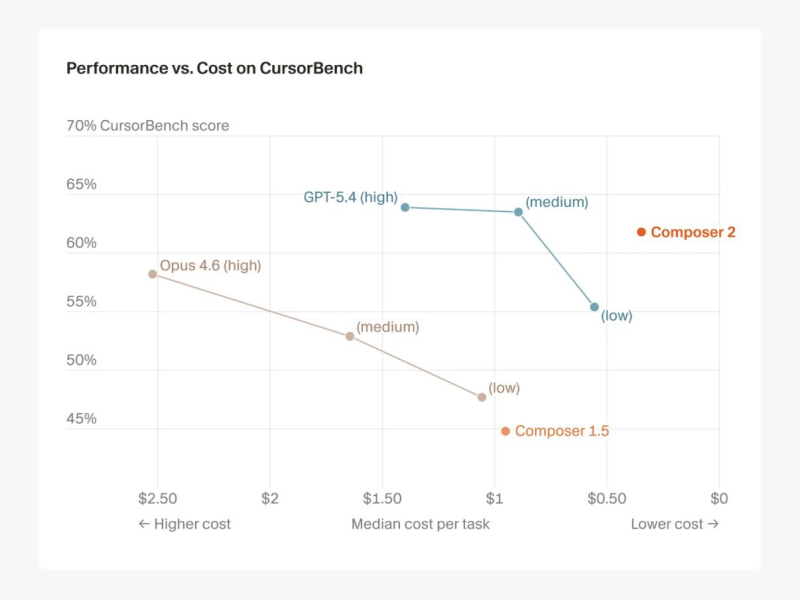
GPT-5.4 still leads at 75.1 on Terminal-Bench 2.0, but Anthropic's Claude Opus 4.6 lands below Composer 2 at 58.0 on the same benchmark. Factor in cost, and the new model delivers around 61% of top-tier performance at a fraction of the price - up from 44% efficiency with the previous version.
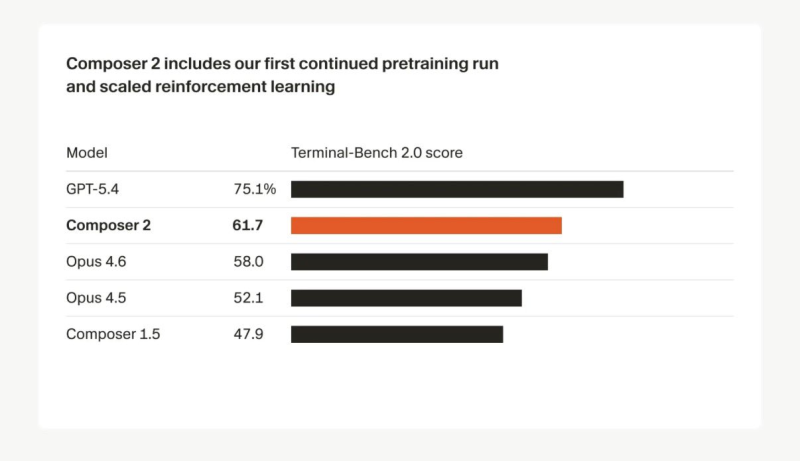
A score of 73.7 on SWE-bench Multilingual rounds out a benchmark profile that's difficult to dismiss. That gap is narrowing fast, and Minimax M2.7's recent entry into the agent race with a 200K context window and 56 SWE-Pro score shows just how crowded - and competitive - this space has become.
fficiency-driven adoption is becoming the defining trend in AI coding, and Composer 2 is positioned squarely at the center of that shift.
$0.50 Per Million Tokens: The Pricing Strategy Reshaping AI Coding Competition
Pricing is where Composer 2 lands its clearest punch. At just $0.50 per million input tokens and $2.50 per million output tokens, it undercuts most comparable models on the market by a significant margin.
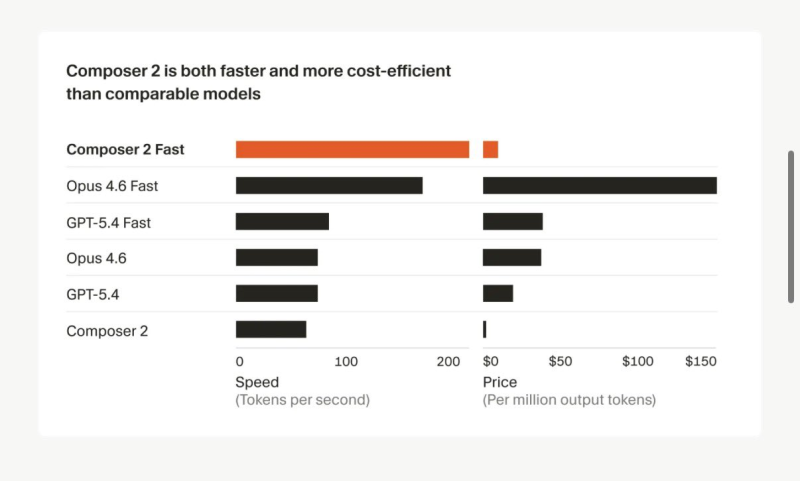
Inference speed compounds the advantage - Composer 2 runs faster than both GPT-5.4 and Opus 4.6 in similar configurations, which matters when you're running thousands of completions a day. Meanwhile, OpenAI's GPT-5.4 Mini hitting 72.1 on OSWorld and outpacing rivals in the 2025 benchmark race confirms that the efficiency push isn't unique to Cursor - it's an industry-wide trend.
The pressure on premium-priced models is only going to increase. Production teams are already re-evaluating their model stacks, and the calculus is shifting toward total cost of ownership rather than headline benchmark scores. Even infrastructure-level changes are in play: Gemini 3.1 Pro's throughput dropping 46% to just 50 tokens per second on Google Vertex illustrates how performance at scale can degrade in ways that matter for real deployments. Against that backdrop, Composer 2's combination of solid benchmarks, fast inference, and aggressive pricing looks less like a niche play and more like a template for where the market is heading.
 Usman Salis
Usman Salis


