 Saad Ullah
Saad Ullah

⬤ Fireworks AI just crushed the competition in inference speed for the Kimi K2.5 thinking model, new benchmark data from Artificial Analysis reveals. The platform hit roughly 184 tokens per second—about 76% faster than the runner-up. Six providers were tested under identical conditions, and Fireworks came out on top for both output speed and time to first token.
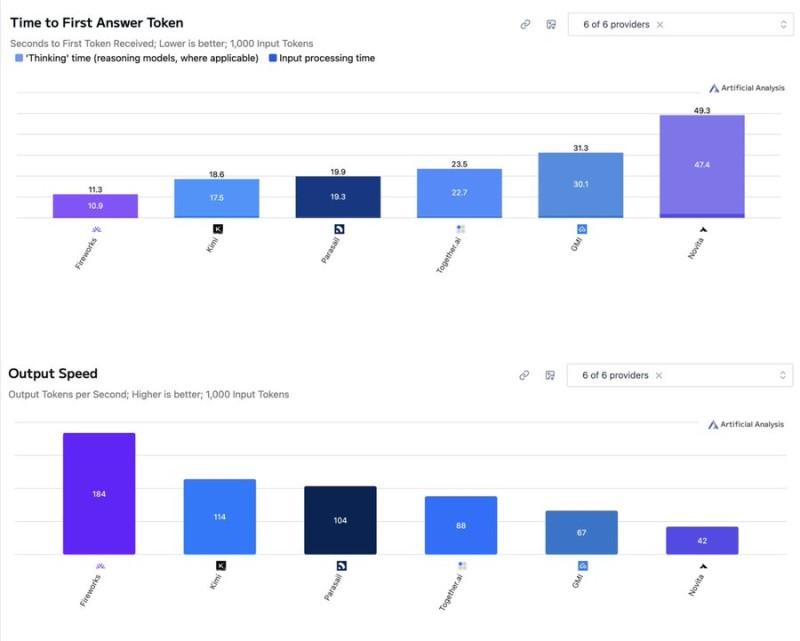
⬤ The gap between Fireworks and everyone else is pretty striking. While Kimi, Parasail, Together AI, Groq, and Novita all delivered respectable performance, none came close to matching Fireworks' throughput. The company also scored near the top for response initiation, meaning users get their first token back quickly and then enjoy sustained high-speed output throughout the generation process.
⬤ For teams building with advanced reasoning models, this matters a lot. Faster inference means less waiting during development cycles and smoother experiences when models need to generate lengthy or complex responses. The results suggest Fireworks has fine-tuned its infrastructure specifically for Kimi K2.5 workloads in ways that other providers haven't quite matched yet.
⬤ The bigger takeaway here is that infrastructure choice isn't just a backend detail—it directly shapes how well your AI actually performs in real-world use. As reasoning models like Kimi K2.5 become standard tools, picking the right inference provider could mean the difference between a system that feels snappy and one that drags. These benchmarks make it clear that optimization at the provider level is just as critical as the model itself.
 Saad Ullah
Saad Ullah


