 Peter Smith
Peter Smith

⬤ A new data generation pipeline has been developed to help code-focused language models get better at handling software security issues. The framework walks through a step-by-step process for creating high-quality security training data for code LLMs. The pipeline trains models to spot vulnerabilities, explain what's wrong, and actually fix the problems using reliable training signals.
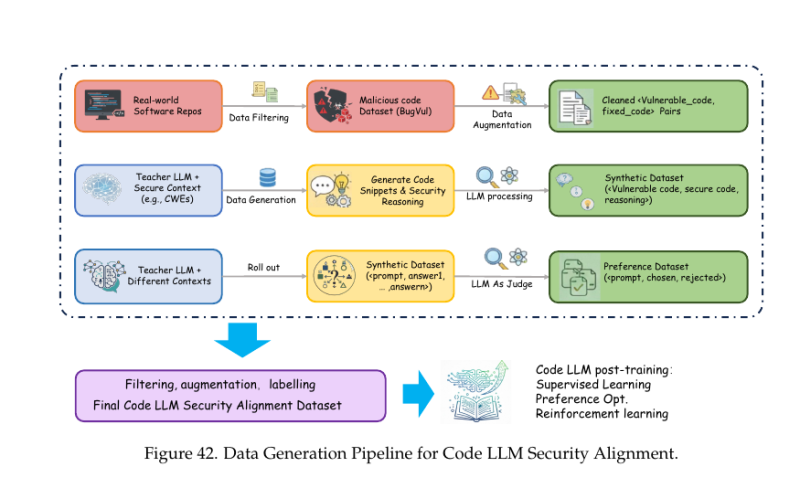
⬤ The process starts with real software repositories where researchers pull known vulnerable code from bug and vulnerability databases. These samples get cleaned up and paired with their fixed versions. This pairing helps models learn actual repair patterns and recognize what secure coding looks like in practice. The data then gets expanded through augmentation while keeping everything structurally consistent.
⬤ A teacher language model with built-in security knowledge handles common vulnerability categories like CWEs and generates additional training data. This teacher creates vulnerable code snippets alongside secure alternatives and explains why code is insecure and how to fix it. The teacher model produces multiple candidate answers for the same problem, which an LLM judge evaluates to label preferred versus rejected responses. This creates a preference dataset ready for supervised learning, preference optimization, and reinforcement learning.

⬤ This pipeline addresses a growing problem: software security risks are climbing as AI-generated code becomes mainstream. By anchoring training data in real vulnerabilities and combining it with structured reasoning and preference signals, the approach makes code LLMs more reliable for security-critical tasks. As demand increases for AI systems that can safely assist in software development, systematic security alignment pipelines like this could set future standards for training and deploying code-generating models.
 Peter Smith
Peter Smith


