 Saad Ullah
Saad Ullah

⬤ Yuan Lab has released Yuan3.0 Ultra, an open-source multimodal mixture-of-experts (MoE) model built for large-scale retrieval and reasoning. The system carries 1.01 trillion total parameters, though only 68.8 billion are active during inference, keeping compute costs far below what a dense trillion-scale model would demand. The launch lands in a competitive moment for frontier AI, as GPT-5.2 hits 33 on LiveCodeBench Pro, a milestone once projected to arrive no earlier than 2030.
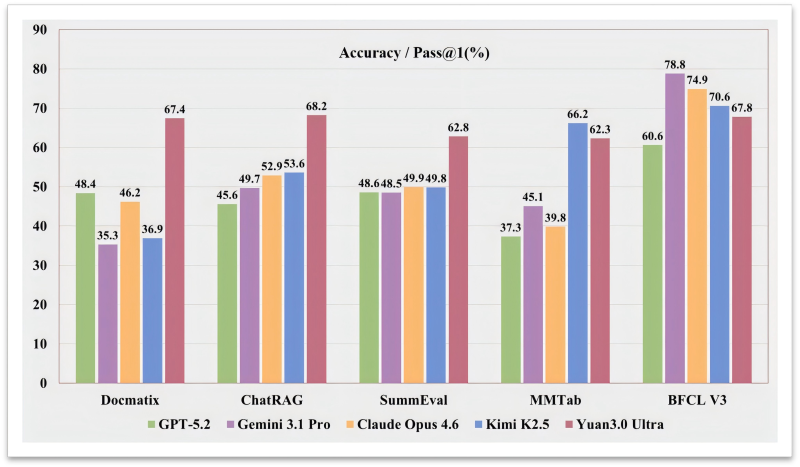
⬤ Benchmark results paint a clear picture. On Docmatix, Yuan3.0 Ultra scored 67.4% accuracy against 48.4% for GPT-5.2, 46.2% for Claude Opus 4.6, 35.3% for Gemini 3.1 Pro, and 36.9% for Kimi K2.5. On ChatRAG the lead holds: Yuan3.0 Ultra reached 68.2% while rivals clustered between 45% and 53%. Additional scores of 62.8% on SummEval and 62.3% on MMTab round out a strong showing across summarization and multimodal table reasoning.
⬤ The architecture introduces Layer-Adaptive Expert Pruning (LAEP), aimed squarely at the uneven token distribution that typically emerges in MoE training. When some experts absorb far more tokens than others, efficiency suffers. LAEP prunes underused experts mid-training, cutting parameter count by about 33% and boosting training efficiency by 49%. That kind of architectural discipline is increasingly relevant as Claude Opus 4.6 solves Knuth's math problem after weeks of human effort, raising the bar for what reasoning systems can actually do.
⬤ Yuan Lab also applied a reinforcement learning method called "fast-thinking" RL, which rewards correct answers that need fewer reasoning steps. The outcome: output tokens dropped 14.38% while accuracy climbed 16.33%. It is a meaningful trade-off in a field where verbosity is often confused with depth. Alongside these gains, multi-agent architectures are gaining traction, with Moonshot AI's Kimi K2.5 running multiple AI agents at once, a sign that scaling AI performance still has plenty of unexplored directions.
 Saad Ullah
Saad Ullah


