 Saad Ullah
Saad Ullah

xAI's Grok Voice Agent has broken into the global top tier of speech AI, posting a 92.9% score on the Big Bench Audio benchmark for speech reasoning. The result puts the model in second place overall and shows that xAI's Grok Voice Agent score of 92.3% on Big Bench Audio rankings is not a one-off result but a consistent signal of where the model sits in a field that is getting more competitive by the month.
A 92.9% Score That Puts Grok Voice in Elite Company
Big Bench Audio tests a model's ability to interpret and reason over audio inputs rather than plain text, making it a more demanding gauge than standard speech transcription metrics.
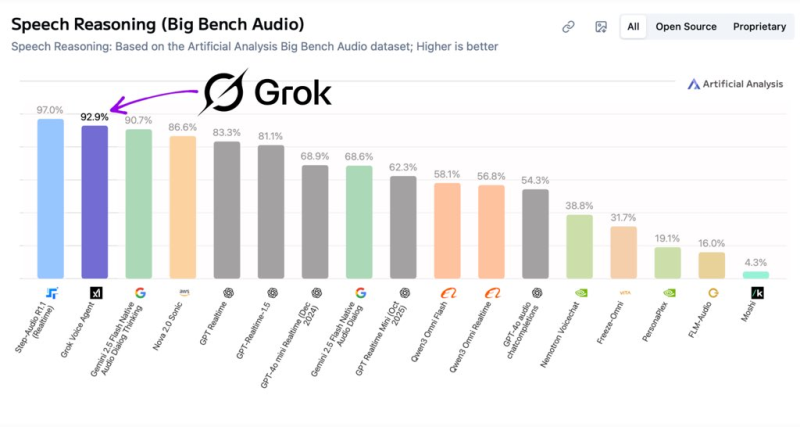
Grok Voice Agent cleared 92.9%, trailing only the top system at roughly 97%. Competing models including Gemini 2.5 Flash Audio and Nova Sonic land in the mid-to-high 80% range, leaving a clear gap between the leaders and the rest of the field.
Designed for extremely low latency, enabling near-instant responses and more natural conversational interaction.
That margin matters because it reflects not just transcription accuracy but the capacity to understand context, intent, and nuance delivered through voice.
Already Running in Tesla and the Grok Ecosystem at Scale
Grok Voice Agent is not a research demo sitting in a lab waiting for a product home. The model is already integrated across Tesla's ecosystem and broader Grok-powered applications, running at a scale that puts low-latency voice reasoning in front of millions of real-world users. That kind of deployment marks a meaningful shift: advanced speech AI is moving out of controlled environments and into consumer hardware, where reliability and response speed are non-negotiable. Rival systems are pushing hard in the same direction, with Gemini 2.5 hitting the 39-minute mark on the METR benchmark, while Gemini 3 is projected to reach 27 hours of autonomous reasoning, widening the frontier of what long-duration AI agents can handle.
The pace of progress across the sector makes any single benchmark snapshot feel temporary. Google's Gemini 3 Flash has already reached 73% accuracy on a long-context benchmark, underlining how quickly both reasoning depth and real-time responsiveness are becoming baseline expectations rather than differentiators. For Grok Voice Agent, a second-place finish today with live deployment at scale is a strong starting position in a race that is clearly far from over.
 Saad Ullah
Saad Ullah


