 Usman Salis
Usman Salis

⬤ Google caught fresh attention after new METR benchmark data revealed how Gemini 2.5 stacks up against the competition. Released in June, the model clocked in at about 39 minutes on the METR_Evals benchmark, landing below the trend line that's been tracking frontier AI systems. The chart places Gemini 2.5 slightly under the capability curve formed by models like GPT-5, Claude Sonnet 4.5, and Grok 4.
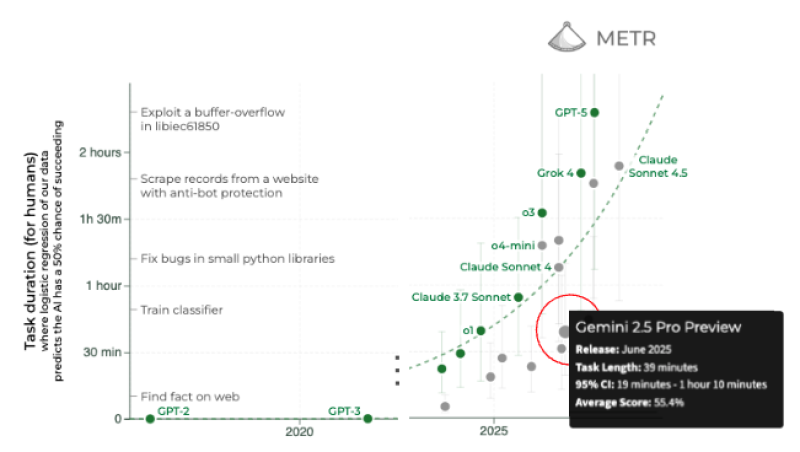
⬤ The METR benchmark tests how long AI systems need to complete tasks that humans have a 50% shot at finishing, covering everything from training classifiers to fixing Python bugs and spotting software vulnerabilities. Gemini 2.5 Pro Preview's metrics show a 39-minute task length, a 95% confidence interval between 19 minutes and 1 hour 10 minutes, and an average score of 55.4%. These numbers put Gemini 2.5 behind the rising curve of task duration that defines more capable frontier models.
⬤ Looking ahead to Gemini 3, if the next model follows the established trend, it would hit somewhere near a three-hour task duration. Current forecasts point to Gemini 3 landing slightly below that at roughly 2.7 hours, with an 80% confidence interval between 1.1 hours and 4.3 hours. The visualization shows this upward climb, where newer systems handle longer task durations as they tackle increasingly complex operations.
⬤ These benchmark results carry weight because METR trajectories have become a key yardstick for measuring frontier AI progress. Gemini 2.5's below-trend performance and Gemini 3's projected numbers shape how the market views Google's competitive standing as the industry pushes toward the next wave of high-capability models. The data influences expectations around capability growth, competitive dynamics in the AI space, and how quickly GOOGL might narrow the gap with top-tier rivals.
 Usman Salis
Usman Salis


