 Usman Salis
Usman Salis

Recent results from the Hieroglyph Benchmark—a specialized test measuring how well large language models think laterally, connecting abstract ideas and solving non-obvious problems—show OpenAI's GPT-5 (High) scoring highest, narrowly beating Google's pre-launch Gemini 3 Pro checkpoint in a tight race for reasoning supremacy.
Current AI Reasoning Performance
AI trader and commentator Leo shared a chart revealing how 13 leading models handled 20 reasoning challenges.
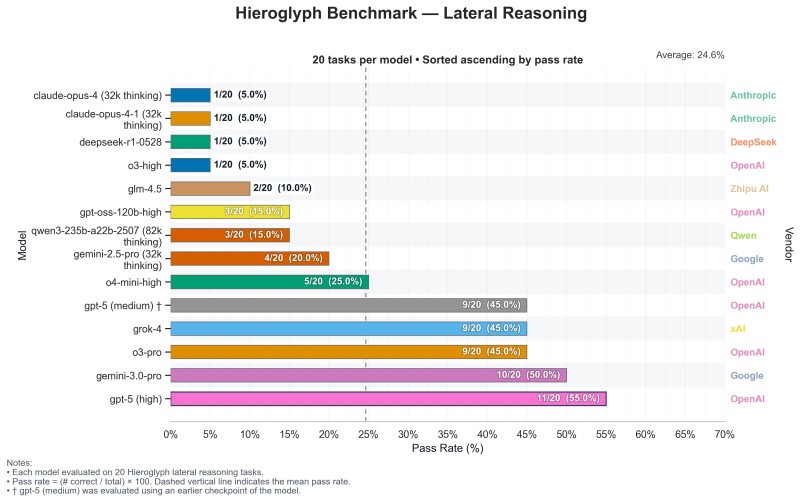
The results highlight a new phase in the AI race — where reasoning and cognitive depth matter more than speed or scale.
Results:
- GPT-5 (High): 55% (11/20 tasks)
- Gemini 3.0 Pro: 50% (10/20)
- GPT-5 (Medium): 45%
- Grok-4: 45%
- O3-Pro: 45%
- O4-Mini-High: 25%
- Gemini 2.5 Pro: 20%
- Claude-Opus-4: 5%
- DeepSeek-R1: 5%
- O3-High: 5%
The overall average was just 24.6%, showing how tough this benchmark is.
The Hieroglyph Benchmark stands apart by testing lateral reasoning — interpreting incomplete clues, spotting hidden patterns, and forming creative solutions. It measures whether AI can truly think, not just recall data.
Gemini 3.0 Pro’s 50% marks a major leap from Gemini 2.5 Pro’s 20%, showing Google’s rapid progress. However, OpenAI remains ahead — GPT-5’s consistent performance across versions reflects deeper structural sophistication and genuine reasoning capability.
Why This Reasoning Matters
This benchmark highlights the next frontier in AI: reasoning under uncertainty. That skill is essential for scientific discovery, strategic analysis in finance or policy, and autonomous agents making decisions without fixed instructions. As basic language fluency becomes standard, reasoning ability will separate leaders from followers in real-world intelligence. The results reflect an industry shift toward cognitive tests measuring genuine understanding rather than surface-level performanc
 Usman Salis
Usman Salis


