 Saad Ullah
Saad Ullah

⬤ Google's Gemini 3 Flash just completed a tough new long-context agentic orchestration benchmark designed around real production constraints. The internal evaluation put models through 26 highly complex scenarios, each packed with over 100,000 tokens of context and requiring accurate function calls using proprietary orchestration logic. All models ran with minimal reasoning settings to simulate speed-critical production environments rather than maxed-out reasoning modes.
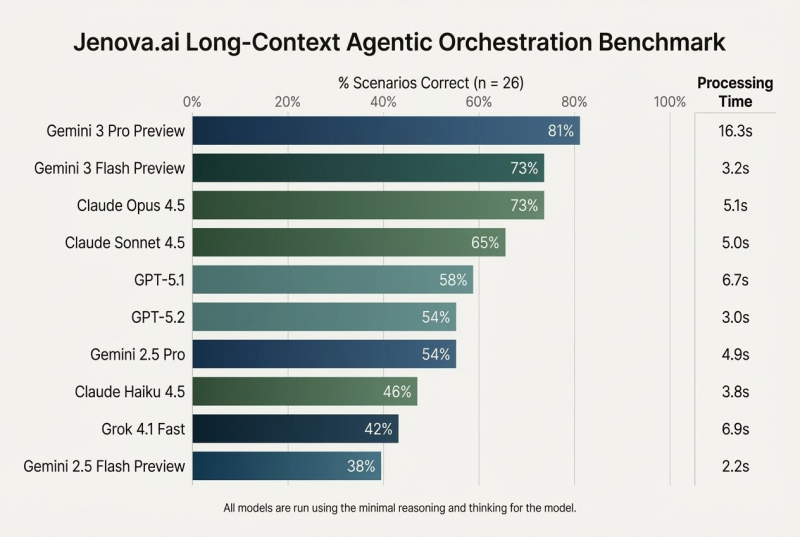
⬤ The benchmark results show Gemini 3 Flash Preview scoring 73% scenario correctness, matching Claude Opus 4.5's 73% and sitting just behind Gemini 3 Pro Preview's leading 81%. Where Gemini 3 Flash really shines is processing speed—averaging just 3.2 seconds per scenario, crushing Gemini 3 Pro Preview's 16.3 seconds and beating Claude Opus 4.5's 5.1 seconds by a comfortable margin.
⬤ Other models showed the classic accuracy-versus-speed trade-off. Claude Sonnet 4.5 hit 65% correctness at around five seconds, while GPT-5.1 managed 58% at 6.7 seconds. Both GPT-5.2 and Gemini 2.5 Pro landed at 54% correctness, though GPT-5.2 ran faster at roughly three seconds. Lower performers included Claude Haiku 4.5 at 46%, Grok 4.1 Fast at 42%, and Gemini 2.5 Flash Preview at 38%. The data makes it clear—Gemini 3 Flash sits near the top for combined correctness and speed.

⬤ These results highlight the growing focus on benchmarks that test long-context handling, orchestration accuracy, and execution speed all at once. For GOOGL, Gemini 3 Flash's performance shows real progress in optimizing models for complex, real-time workflows where both latency and correctness matter. As AI systems handling extended contexts and multi-step actions become standard, these kinds of evaluations will likely drive how platforms get compared and chosen across enterprise and developer ecosystems.
 Saad Ullah
Saad Ullah


