 Saad Ullah
Saad Ullah

⬤ Anthropic launched Claude Opus 4.6, their latest Opus-class model packing a 1M token context window and upgraded reasoning capabilities. The model crushed MRCR v2 testing, which challenges AI to dig out eight specific facts buried deep inside massive prompts.
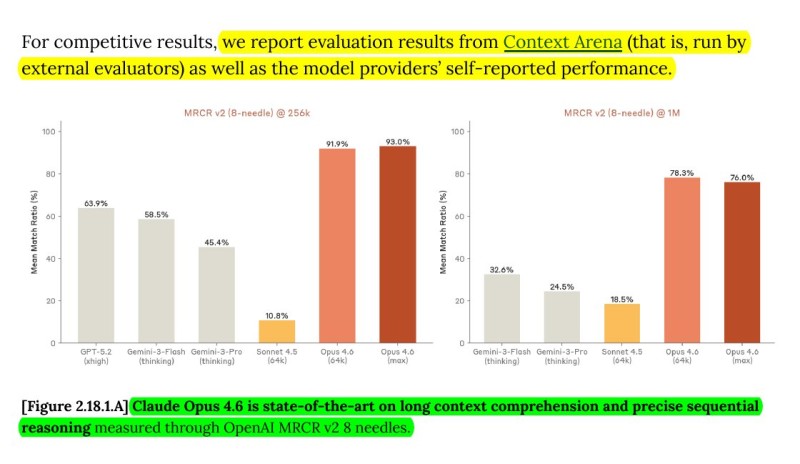
⬤ On MRCR v2's 256k token test, Claude Opus 4.6 hit between 91.9% and 93.0%. GPT-5.2 managed around 63.9%, while Gemini 3 Pro landed at roughly 45.4%. When they cranked it up to 1M tokens, Claude Opus 4.6 pulled 78.3% in one setup and 76.0% in another—Gemini 3 Pro only scraped 24.5%. GPT-5.2 didn't even show up in the 1M token results.
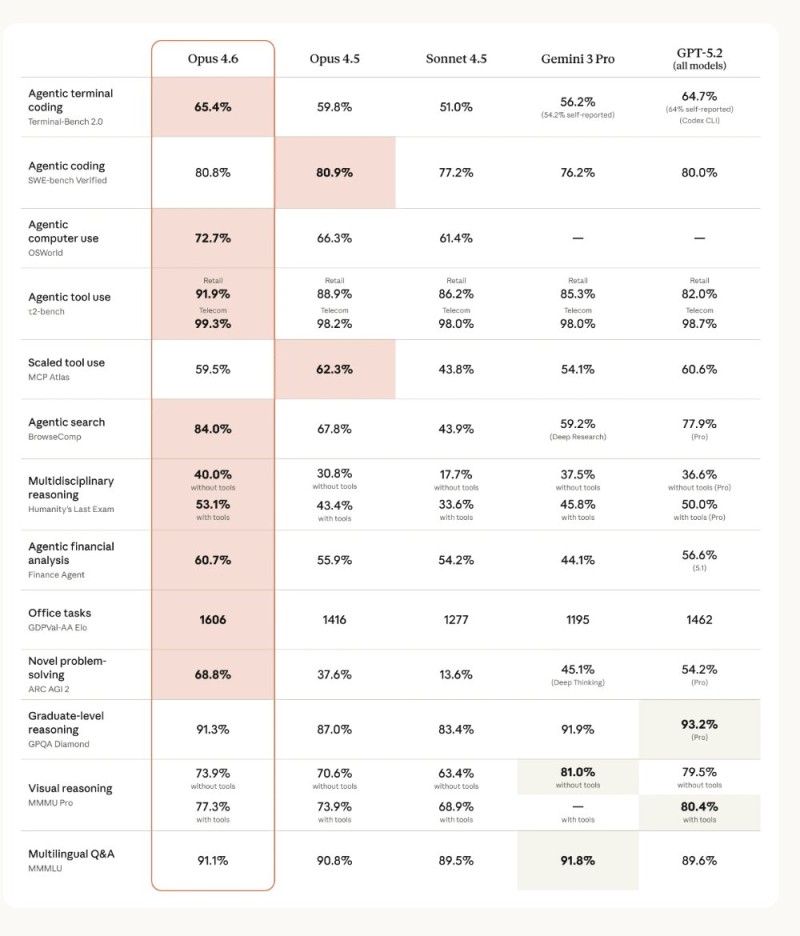
⬤ The model showed solid gains across other benchmarks too. Terminal-Bench agentic coding jumped from 59.8% to 65.4%. ARC AGI-2 problem solving rocketed from 37.6% to 68.8%. BrowseComp agentic search hit 84.0% versus GPT-5.2's 77.9%. A few metrics stayed flat or dipped slightly—SWE-bench Verified held steady around 80.8%, and Scaled Tool Use dropped from 62.3% to 59.5%.

⬤ The release brings adaptive effort levels and context compaction while boosting large-context processing power. These results show real progress in AI systems built to analyze massive documents, pull scattered information together, and handle complex reasoning across huge inputs.
 Saad Ullah
Saad Ullah


