 Saad Ullah
Saad Ullah

As AI systems push deeper into enterprise workflows, research pipelines, and real-time search, one metric is climbing the priority list: hallucination rate. Grok 4.20 is now drawing attention not for raw intelligence benchmarks, but for something arguably more valuable in production settings - how rarely it makes things up. With a 22% hallucination rate on targeted evaluations, it ranks as the most factually grounded model among the current leading systems.
Grok 4.20's 22% Hallucination Rate Undercuts Key Competitors
Benchmark data places Grok 4.20 clearly ahead of its direct competition on accuracy. Grok 4.20 tops search arena benchmarks and scores around 22% on hallucination evaluations, compared to Claude 4.5 Haiku at 26%, MiniMax V2 Pro at 30%, and GLM-5 at 34%. In this context, lower is better - each percentage point represents fewer fabricated or misleading outputs. The gap between Grok 4.20 and GLM-5 is significant: more than 12 percentage points separate the two.
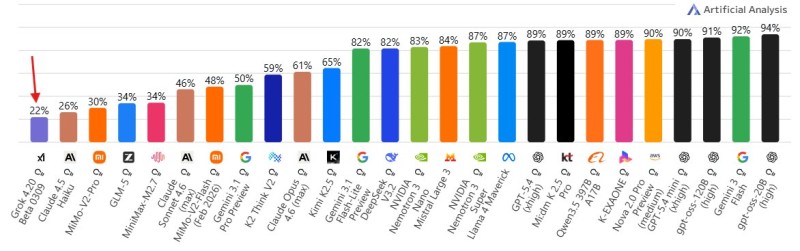
The chart data also reveals a wide spread across the AI landscape. Many advanced models cluster considerably higher on the hallucination scale, making Grok 4.20 a genuine outlier on the reliable end. The model consistently prioritizes factual grounding, even when that comes at the cost of reasoning performance in other categories. That trade-off is increasingly seen as acceptable for search-style use cases where one wrong answer can undermine user trust.
Why Accuracy Is Becoming the New Benchmark in AI Competition
The attention around Grok 4.20's hallucination rate reflects a broader shift in what the industry values. Speed and capability scores still matter, but as AI gets woven into Microsoft Copilot autonomous agent workflows and similar enterprise tools, factual reliability is quickly becoming non-negotiable. A model that sounds confident but produces incorrect outputs creates liability - not value.
Competing labs are responding. GLM-5 breakthrough model competing with GPT-5 represents one data point in a wider pattern: every major provider is now investing in reducing hallucinations, not just improving reasoning or speed. Grok 4.20 demonstrates that a model can lead on accuracy without necessarily leading across every benchmark, and that tradeoff may be exactly what reliability-focused deployments need.
 Saad Ullah
Saad Ullah


