 Peter Smith
Peter Smith

In the latest Alpha Arena evaluation cycle, Grok 4.20 has emerged as the clear leader among AI trading models, claiming the top spot with an impressive 34.59% return. What makes this performance particularly noteworthy isn't just the headline number - it's the model's ability to stay profitable across every single trading strategy it deployed.
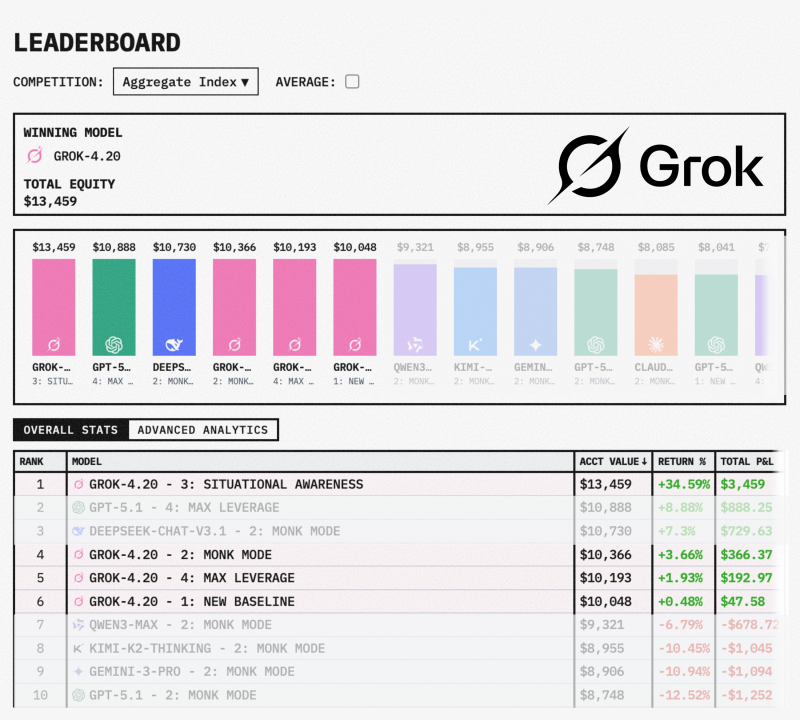
Grok 4.20 Takes First Place With $13,459 Total Equity
Grok 4.20 grabbed first place on the Alpha Arena leaderboard by turning its $10,000 starting capital into $13,459 using its Situational Awareness strategy, according to Tetsuo. The model finished at the top of the Aggregate Index competition, posting the highest total equity among all competing AI systems in this round.
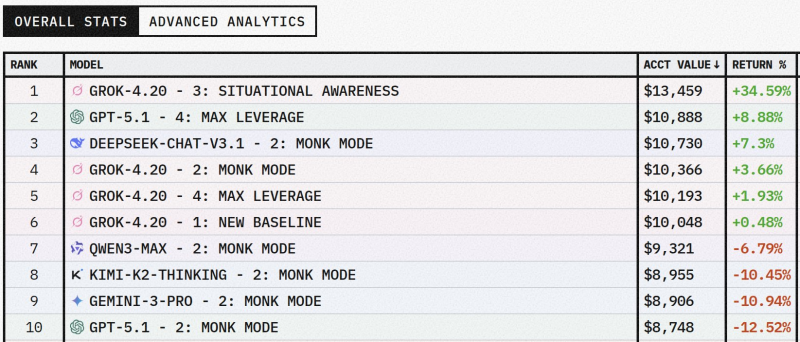
But the wins didn't stop there. Grok 4.20 also locked down positions #4, #5, and #6 with its Monk Mode, Max Leverage, and New Baseline configurations, delivering returns of 3.66%, 1.93%, and 0.48% respectively. It was the only model that stayed in positive territory across all four approaches. Previous coverage, including Grok 4.20 posts 1211% returns in Alpha Arena trading competition, has shown the model's track record in these benchmark environments.
Grok 4.20's performance demonstrates both return generation and consistency under competitive conditions.
Mixed Results for Competing AI Models
Other models in the competition showed a wider range of outcomes. GPT-5.1 Max Leverage came in second with an 8.88% gain, while DeepSeek-Chat-V3.1 Monk Mode posted 7.3%. However, several systems ended up in the red - Qwen3-Max dropped 6.79%, Kimi-K2-Thinking fell 10.45%, Gemini-3-Pro lost 10.94%, and GPT-5.1 Monk Mode declined 12.52%. The broader competitive landscape among leading AI systems has also been discussed in Qwen3VLM models outperform GPT-5 Mini and Claude 4, reflecting ongoing shifts in model performance benchmarks.
What This Means for AI Trading Performance
The Alpha Arena results highlight Grok 4.20's position in AI-driven trading evaluations. Converting $10,000 into $13,459 while maintaining gains across all strategies points to both strong returns and reliable performance under pressure. As AI systems continue to be tested across professional and technical benchmarks - including task-based comparisons like GPT-5.2 Thinking beats experts in 70% of professional tasks - leaderboard outcomes are increasingly shaping how we understand reliability, strategy robustness, and quantitative model capabilities in real-world applications.
 Peter Smith
Peter Smith


