 Usman Salis
Usman Salis

⬤ GPT-5.3-Codex set a new standard on the IBench benchmark with 86% accuracy in medium reasoning mode, establishing a significant lead over competing models. Gemini-3.1-pro-preview secured second place at 69%, revealing a 17-percentage-point gap in this specialized evaluation. The benchmark measures coding capabilities and reasoning performance across multiple task categories, with human baseline performance set at 100% for reference. Long-duration testing has shown strong results as well - OpenAI GPT-5.3-Codex hitting a 6.5-hour task success horizon per METR analysis demonstrates the model's sustained performance capabilities beyond quick evaluations.
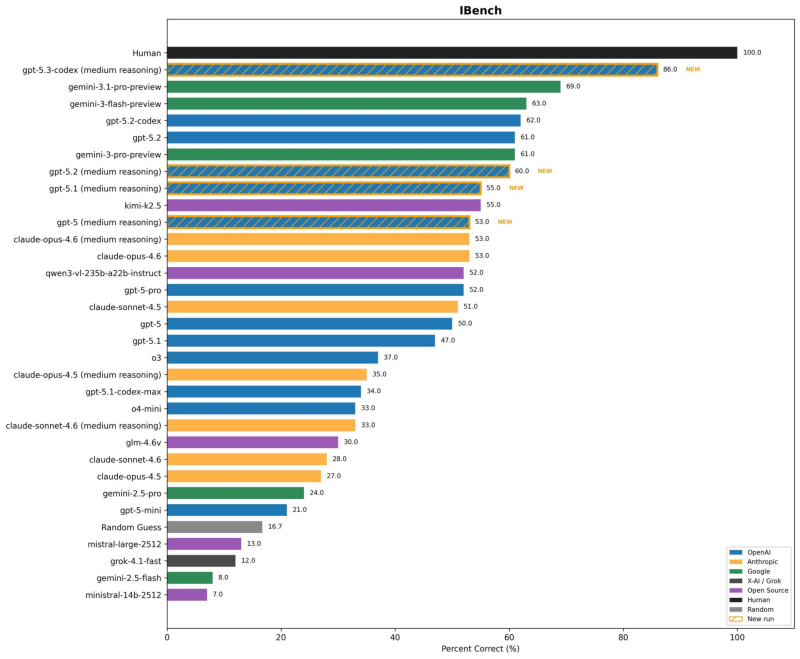
⬤ The middle tier of the leaderboard shows tighter competition, with Gemini-3-flash-preview reaching 63% and GPT-5.2-codex posting 62%. GPT-5.2 and Gemini-3-pro-preview both landed at 61%, while Claude-opus-4.6 in medium reasoning mode matched GPT-5 at 53%. Rankings continue to shift as new benchmarks emerge - Claude Opus 4.6 leading as SWEBench reshapes AI coding rankings illustrates how different evaluation frameworks can produce varying results. Multiple models clustered in the low-50s range suggest similar baseline capabilities, though real-world application performance may differ from standardized testing.
⬤ Infrastructure considerations add complexity to pure benchmark comparisons. Production deployment reveals performance characteristics that laboratory testing may not capture fully. Reports indicate Gemini 3.1 Pro throughput dropping to 46-50 TPS on Google Vertex, showing how processing speed under load can diverge from accuracy scores. System efficiency, latency management, and sustained throughput become critical factors when models move from benchmark environments to live production systems serving concurrent users.
⬤ The IBench results confirm GPT-5.3-Codex's position at the top of current coding and reasoning evaluations. The 17-point advantage over Gemini 3.1 Pro represents meaningful differentiation in model capabilities. As AI providers continue refining their systems, structured benchmark comparisons provide measurable insights into competitive positioning, though deployment context remains essential for understanding real-world performance differences across platforms.
 Usman Salis
Usman Salis


