 Marina Lyubimova
Marina Lyubimova

⬤ OpenAI's newest system card shows GPT-5.2 makes far fewer mistakes than previous models. The update reveals hallucinations dropped by roughly 30 to 40 percent—one of the biggest improvements in factual accuracy across the GPT-5 lineup. This comparison is based on testing across thousands of prompts designed to mirror real ChatGPT conversations.
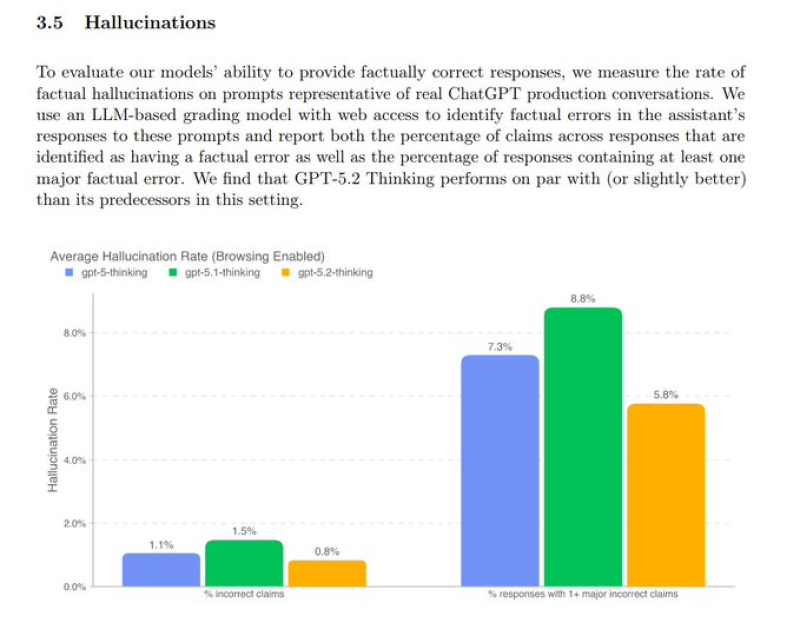
⬤ The numbers tell a clear story. GPT-5 Thinking produced incorrect claims in about 1.1 percent of cases, GPT-5.1 Thinking hit 1.5 percent, while GPT-5.2 Thinking dropped to just 0.8 percent. The gap gets even wider when looking at responses with at least one major error: GPT-5 Thinking showed 7.3 percent, GPT-5.1 Thinking 8.8 percent, and GPT-5.2 Thinking came in at 5.8 percent.
⬤ OpenAI tested this using an AI grading model with web access to catch factual mistakes in generated responses. This approach allows direct comparison between model versions using real-world prompts. The company says GPT-5.2 matches or beats its predecessors, proving that design and training improvements are paying off.
⬤ Better accuracy matters tremendously for AI's commercial future. Factual reliability remains the biggest concern for businesses considering AI adoption at scale. As models like GPT-5.2 prove they can deliver consistent, trustworthy results, they become practical for complex enterprise workflows—pushing the entire industry toward wider deployment of advanced AI systems.
 Marina Lyubimova
Marina Lyubimova


