 Eseandre Mordi
Eseandre Mordi

⬤ Artificial Analysis just dropped fresh benchmark results for Claude Sonnet 4.6, and the numbers are hard to ignore. Sonnet 4.6 scored 51 points in the Intelligence Index, tying GPT-5.2 and sitting just two points behind Claude Opus 4.6 at 53. It's the first time Anthropic has claimed the top two slots simultaneously.
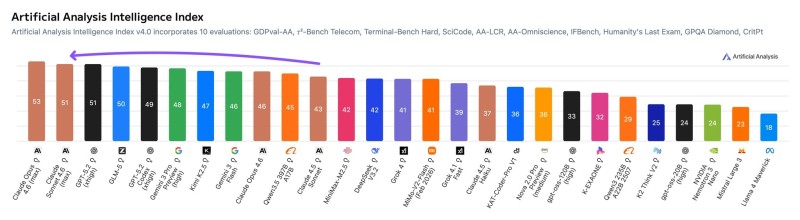
⬤ The index pulls from ten separate evaluations covering reasoning, coding, science, and agentic tasks. Sonnet 4.6 didn't just keep pace, it actually beat Opus 4.6 in GDPval-AA and TerminalBench, making it the strongest tested model for agentic use cases. The gap between the two tiers narrowed from seven points in the previous generation to just two. Related coverage explores AI coding rankings reshaping model competition.
Sonnet 4.6 used roughly 74 million output tokens in max effort adaptive thinking mode, about three times Sonnet 4.5.
⬤ Better performance does come with a bigger bill. Running the full evaluation cost around $2,088, compared to about $733 for Sonnet 4.5. That said, it still came in cheaper than Opus 4.6 thanks to lower per-token pricing. Enterprise teams are increasingly looking at enterprise task accuracy improvements from Claude Sonnet 4.6 to justify the jump in compute costs.
⬤ On the technical side, Sonnet 4.6 ships with a 1 million token context window and up to 128K output tokens. It's available now through Google Vertex, AWS Bedrock, and Microsoft Azure. As the gap between frontier models tightens, these benchmarks make clear that capability gains are increasingly coming hand-in-hand with higher compute demands.
 Eseandre Mordi
Eseandre Mordi


