 Victoria Bazir
Victoria Bazir

Box has shared early access results from testing Anthropic's Claude Sonnet 4.6 inside its Box AI platform, and the numbers are hard to ignore.
Claude Sonnet 4.6 Delivers Real-World Accuracy Improvements
Running the model through its Box AI Complex Work Eval, the company recorded a 15 percentage point jump in performance compared to Claude Sonnet 4.5. As Aaron Levie noted, this wasn't a lab benchmark exercise but an attempt to replicate actual workplace scenarios involving large document sets, report generation, due diligence reviews, and expert analysis.
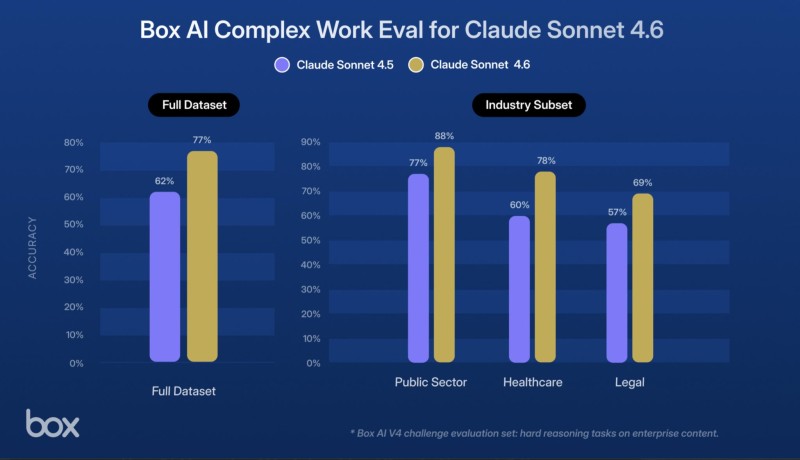
The sector-level results tell a clear story. Public sector accuracy climbed from 77% to 88%, healthcare moved from 60% to 78%, and legal tasks went from 57% to 69%. Overall, across the full dataset, accuracy rose from 62% to 77%.
The goal of the testing was to approximate real workplace scenarios rather than benchmark-only measurements.
Box credited the gains to better reasoning, improved tool usage, and stronger handling of complex structured information. The company also noted that similar improvements appeared across additional industries beyond the three highlighted.
What This Means for Enterprise AI Workflows
Claude Sonnet 4.6 is set to become available inside Box AI Studio, giving enterprises the ability to build custom agents on top of the model. For organizations dealing with document-heavy processes, this is a meaningful step forward.
The results point to a broader shift in how AI performance is being measured. Rather than relying purely on standardized benchmarks, platforms like Box are increasingly evaluating models against the kind of multi-step, context-rich tasks that workers actually face day to day.
For industries like healthcare and legal, where accuracy directly affects outcomes, a jump from 60% to 78% or 57% to 69% isn't just a statistic. It's the difference between a tool that assists and one that can be genuinely trusted.
 Victoria Bazir
Victoria Bazir


