 Eseandre Mordi
Eseandre Mordi

⬤ Anthropic's Claude 4.5 Opus now leads the updated LiveBench leaderboard, which measures real-world large language model performance across reasoning, coding, agentic coding, and mathematics. The benchmark methodology got a complete overhaul during the holiday period to cut down on gaming and better capture how these models actually perform day-to-day. Claude 4.5 Opus landed a Global Average of 76.20, breaking down to 80.09 in reasoning, 79.65 in coding, 63.33 in agentic coding, and 94.52 in mathematics.
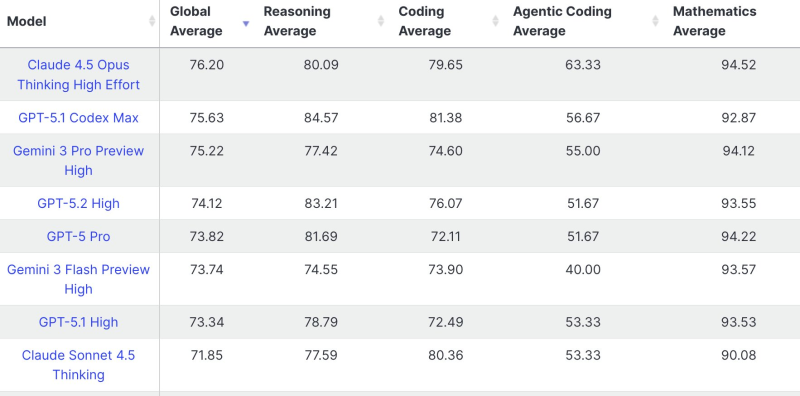
⬤ GPT-5.1 Codex Max grabbed second place with a 75.63 Global Average, while Gemini 3 Pro Preview High came in third at 75.22. GPT-5.2 High scored 74.12, GPT-5 Pro hit 73.82, and Gemini 3 Flash Preview High posted 73.74. GPT-5.1 High landed at 73.34, with Claude Sonnet 4.5 Thinking scoring 71.85.
⬤ Open-weights models made a strong showing in the new rankings. Kimi K2 Thinking leads the open-weights pack, with DeepSeek V3.2 and GLM 4.7 also making the top-rated list of publicly available systems. The benchmark team specifically designed this revision to stop "benchmark maxxing"—where models get tuned just to ace public tests instead of showing real capability.

⬤ The updated LiveBench release confirms the ranking now mirrors how large language models perform in actual use cases. The maintainers plan to keep refining the benchmark to ensure scores stay resistant to gaming while accurately reflecting practical model performance.
 Eseandre Mordi
Eseandre Mordi


