 Victoria Bazir
Victoria Bazir

⬤ A team from the Chinese Academy of Sciences and UCAS introduced BridgeV2W, an embodied robotics AI model that lets robots anticipate and visualize upcoming arm movements before execution. As reported by jiqizhixin, BridgeV2W converts robot motion data into structured visuals using embodiment masks to guide generative video prediction. This mirrors broader AI architectural refinements, including an AI translation framework reporting a 41% quality improvement, where structural changes produced measurable performance gains.
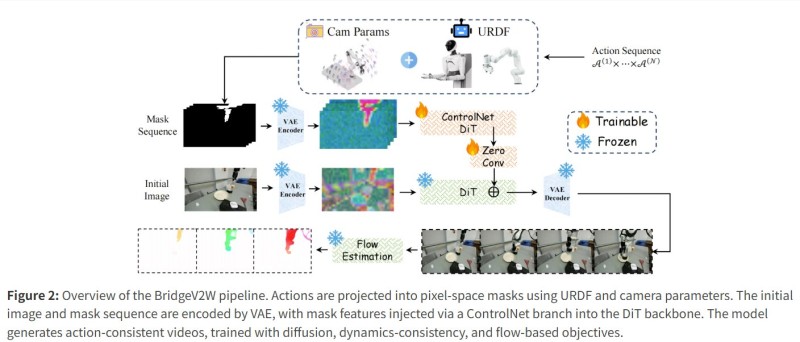
⬤ The BridgeV2W pipeline projects robot actions into pixel-space masks using URDF parameters and multi-camera input. These masks and the initial environment image are encoded via a VAE encoder, with mask features injected into a diffusion transformer backbone through a ControlNet branch. By focusing on motion flow rather than static background reconstruction, the model generates action-consistent video sequences from varied viewpoints. This kind of structured execution mirrors automation breakthroughs like an AI system that generated $10,000 in seven hours through real work tasks, illustrating AI's growing role in real-world operational environments.
⬤ BridgeV2W outperforms existing state-of-the-art models on benchmark robotics datasets including DROID and AgiBot G1 for both single-arm and dual-arm setups, even in previously unseen environments. By prioritizing flow visualization over traditional frame prediction, the system improves planning and policy evaluation compared to prior visual robotics models. This evolution parallels advances like a universal robot control model trained on 20,000 hours of real-world data, which similarly leverages large-scale experience to boost robotic generalization.
⬤ BridgeV2W highlights how generative visual models and embodied robotics are converging. Predictive visualization has real implications for robotic planning, simulation, and task execution - potentially improving decision-making in automation systems. As robotics AI evolves, frameworks that translate discrete actions into reliable visual forecasts could set new standards in robot perception and embodied world modeling across both research and industrial deployment.
 Victoria Bazir
Victoria Bazir


