 Saad Ullah
Saad Ullah

Multimodal AI has long had a core problem: models that see well don't always reason well. An international research team just took a concrete step toward fixing that with ThinkMorph, a system that fuses visual understanding and language reasoning into a single, continuous process rather than two separate pipelines that pass data back and forth.
How ThinkMorph Merges Vision and Language Into One Chain
ThinkMorph builds progressive reasoning chains that alternate between image grounding and structured text logic, holding both modalities active at the same time. It handles tasks like jigsaw assembly, spatial navigation, visual search, and chart interpretation without handing off work between isolated modules.
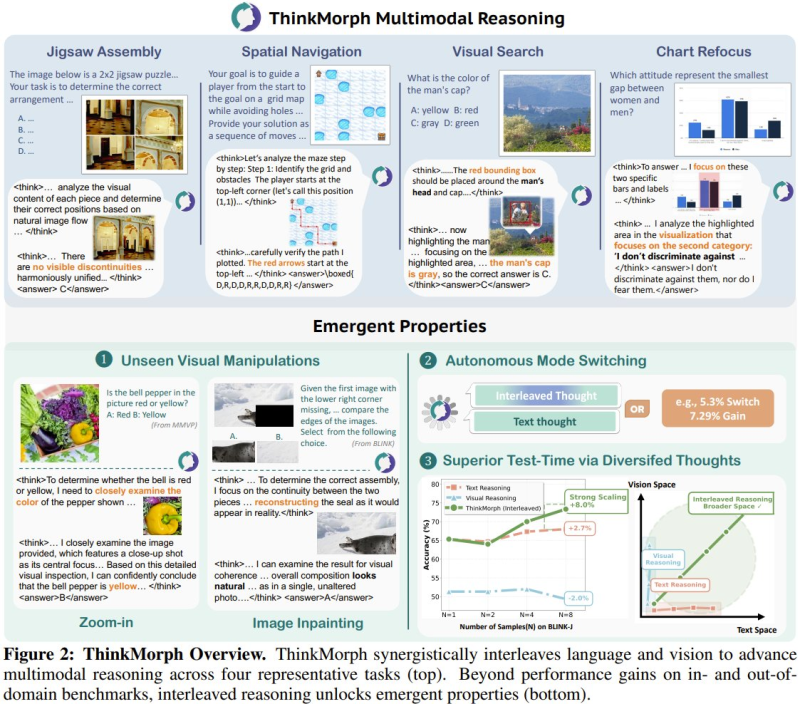
That interleaved structure directly reduces the compounding errors common in two-stage systems. The transparency matters too: research shows AI models conceal their reasoning 75% of the time, making step-by-step chains like these a real improvement in interpretability.
34.7% Benchmark Gain and Capabilities Nobody Trained For
The results speak clearly. ThinkMorph posts a 34.7% average improvement on vision-centric benchmarks and surfaces emergent behaviors the team never explicitly built in: unseen visual manipulation, adaptive reasoning, and autonomous mode-switching between text and vision tasks. It matches or beats larger proprietary models in several head-to-head evaluations. Coordination at scale stays a challenge across the industry, though: LLM agent consensus still breaks down at scale, and ThinkMorph hasn't solved that problem either.
ThinkMorph's release reflects a broader realignment in AI development. Structured reasoning and reliable data handling are becoming inseparable, a pattern also visible in the infrastructure layer: TrustSQL's 99% accuracy gain signals a new phase in AI data systems. Taken together, these developments suggest the next leap in AI capability will come from deeper cross-modal integration, not from pushing a single modality further on its own.
 Saad Ullah
Saad Ullah


