 Victoria Bazir
Victoria Bazir

⬤ ModelScope rolled out STEP3-VL-10B, an open multimodal AI that packs serious visual smarts and reasoning power into a surprisingly compact package. Even with fewer than 10 billion parameters, this thing's putting up state-of-the-art numbers across major benchmarks—going head-to-head with heavyweights like GLM-4.6V-106B, Qwen3-VL-235B, Seed-1.5-VL-Thinking, and Gemini-2.5-Pro.
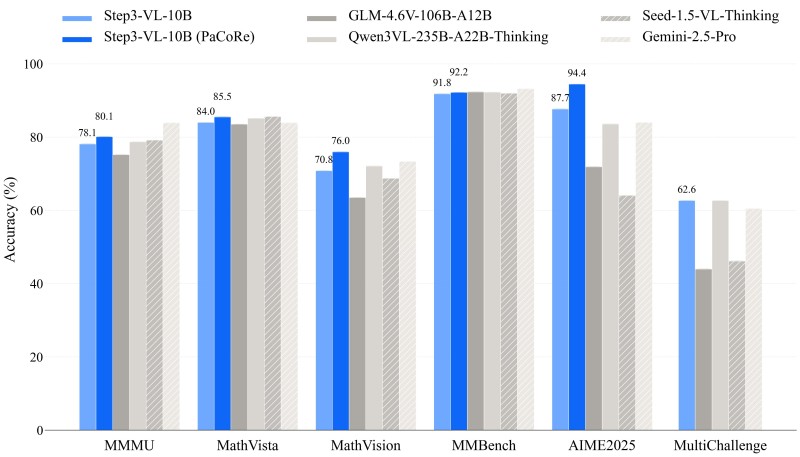
⬤ The benchmark scores tell a pretty compelling story. STEP3-VL-10B hit around 78% accuracy on MMMU, jumping to about 80% when the PaCoRe enhancement kicked in. MathVista performance climbed to roughly 85.5%, while MathVision landed around 76% with PaCoRe enabled. What's wild is these numbers put a sub-10B model right alongside—or even ahead of—models with 10-20 times more parameters on vision-heavy reasoning tasks.
⬤ Things get really interesting on MMBench and AIME 2025. STEP3-VL-10B pulled approximately 92.2% accuracy on MMBench, while the PaCoRe variant crushed AIME 2025 with 94.4%—leading its entire weight class. MultiChallenge scores came in above 62%, beating several much larger models. The secret sauce? Training on roughly 1.2 trillion tokens plus over 1,400 rounds of reinforcement learning that combined RLHF and RLVR techniques. Under the hood, it's running a PE-lang visual encoder paired with a Qwen3-based decoder and handles high-resolution multi-crop visual inputs.

⬤ What makes this launch worth paying attention to is the efficiency angle. We're seeing a compact model deliver performance that used to require massive parameter counts. When something 10-20 times smaller matches or beats the big players, it signals a real shift toward smarter, leaner AI development. This could reshape how we think about deploying multimodal systems—especially when you need deep reasoning and visual understanding without the computational overhead.
 Victoria Bazir
Victoria Bazir


