 Usman Salis
Usman Salis

⬤ Z AI has released two new open models on its platform - GLM-4.6V with 106 billion parameters besides GLM-4.6V-Flash with 9 billion parameters. Both became available at once through Z AI Chat and through the API. Fresh tests on eight key benchmarks - AIME 25, GPQA, LiveCodeBench v6, SWE-bench Verified, HLE, BrowseComp, Terminal-Bench plus r²-Bench - place the GLM-4.6 family beside the best systems as demand grows for models that code and reason with high efficiency.
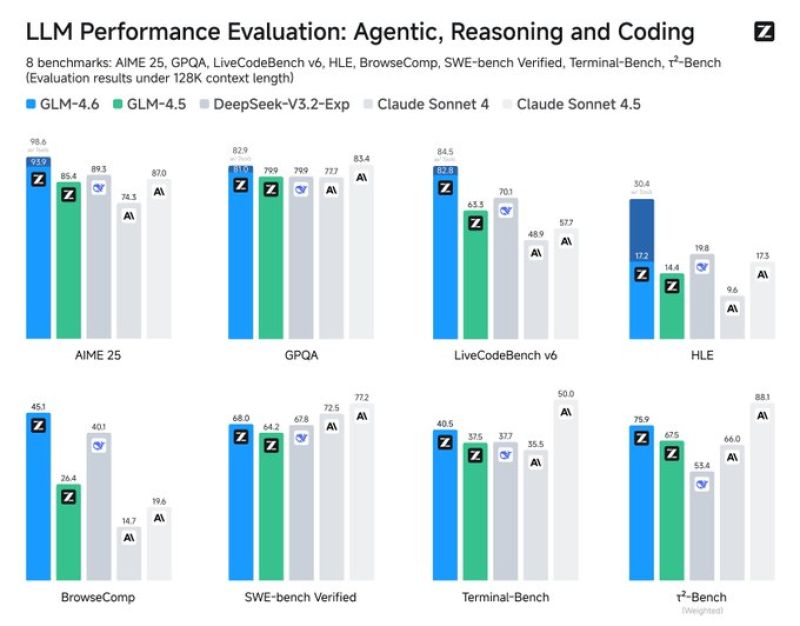
⬤ The benchmark sheet shows GLM-4.6V at 98.6 on AIME 25, above Claude Sonnet 4.5 at 87.0 but also DeepSeek-V3.2-Exp at 89.3. On GPQA it reaches 82.9, just under Claude Sonnet 4 at 83.4. LiveCodeBench v6 gives GLM-4.6 84.5, ahead of Claude Sonnet 4.5 at 70.1. For HLE it attains 30.4, far above Claude Sonnet 4 at 14.4. Coding tests remain solid - BrowseComp 45.1, SWE-bench Verified 68.0, Terminal-Bench 40.5. The weighted r²-Bench records 75.9 for GLM-4.6 versus 66.0 for Claude Sonnet 4.5.
⬤ GLM-4.6V-Flash, the lighter 9-billion-parameter model, earns lower yet still competitive figures on the same tests offering users a quicker and less costly choice. The launch underlines Z AI's effort to widen its ecosystem through both high-capacity as well as speed-oriented models setting it against Claude Sonnet, DeepSeek experimental builds and other enterprise LLM vendors. The comparison also shows steady gains in agent style work like code help and structured problem solving.

⬤ Those figures show that rivalry among models is intensifying as the distance between top developers shrinks. With the market now stressing coding skill, mathematical reasoning or autonomous task completion, Z AI's scores reinforce the wider move toward open, high performance systems that serve enterprise and developer alike. The rising uniformity across benchmarks points to evolving standards as the coming wave of AI roll outs emerges.
 Usman Salis
Usman Salis


