 Peter Smith
Peter Smith

Most AI training systems reward agents for getting the right answer at the end. But what happens when an agent reaches a correct conclusion through flawed logic? That's the exact problem a new framework called Reagent is designed to fix.
Developed by researchers from The Chinese University of Hong Kong and Meituan, Reagent goes beyond binary success-or-failure rewards. Instead, it evaluates each intermediate reasoning step and delivers structured critiques that guide the agent toward better decision-making along the way. It's a meaningful shift in how we think about training AI to reason, not just perform.
How Reagent's Step-by-Step Critique System Works
At the core of Reagent is a reasoning reward model embedded directly into the agent workflow. As an agent interacts with tools like search engines and browsing modules, it generates intermediate outputs at each stage. Reagent then analyzes those outputs - flagging missing steps, logical inconsistencies, ambiguous interpretations, and inefficient tool usage.
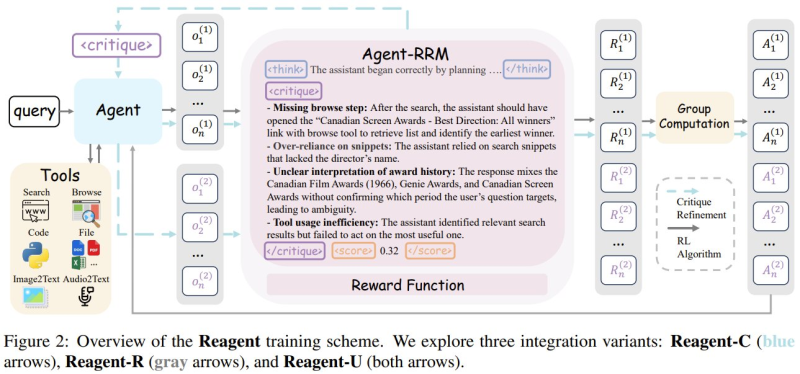
These critiques feed into a reinforcement learning loop, giving the agent richer, more actionable feedback than a simple "right or wrong" signal. The result is structured refinement rather than guesswork. This kind of benchmark-driven evaluation is part of a broader push in the field, echoed by initiatives like Alibaba's MobilityBench, which stress-tests LLM route-planning agents across 100,000 queries in 22 countries.
43.7% on GAIA and 46.2% on WebWalkerQA: The Numbers Behind the Claims
The results are hard to dismiss. Across 12 reasoning benchmarks, Reagent posted 43.7% on GAIA and 46.2% on WebWalkerQA - both solid improvements over baseline approaches, particularly on multi-step tasks requiring complex retrieval and sequential decision-making.
These gains speak to a wider competitive dynamic in AI research. Chinese institutions are pushing aggressively on reasoning capabilities, a trend that aligns with reports of Chinese AI leaders estimating a 20% chance of catching OpenAI within the next five years.
What Reagent ultimately represents is a prioritization of reasoning transparency. As AI agents take on more complex, tool-heavy tasks in the real world, training methods that hold them accountable at every step - not just the last one - may prove to be the more durable path forward.
 Peter Smith
Peter Smith


