 Peter Smith
Peter Smith

⬤ Researchers from MIT CSAIL, Virginia Tech, the University of Virginia, and Michigan State University have introduced a framework called Plan and Budget, built to improve how large language models handle complex reasoning tasks. The system rethinks how models allocate their token "thinking budget" during inference, targeting a core inefficiency that most current approaches leave unresolved.
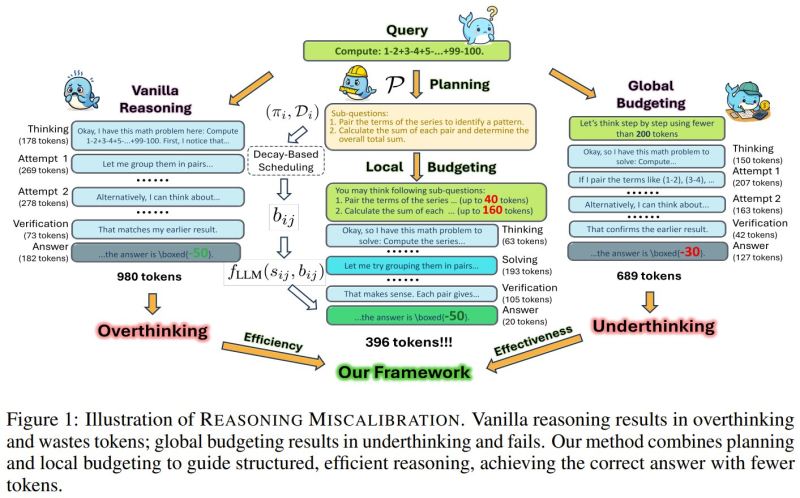
⬤ The central problem the framework tackles is reasoning miscalibration. Standard models either "overthink," burning tokens on steps that add nothing, or "underthink," rushing to wrong answers. Plan and Budget breaks tasks into structured sub-questions and assigns token budgets based on actual complexity. This mirrors what multi-agent AI systems outperforming single models have demonstrated: structured task handling produces measurably better results.
⬤ The numbers are hard to ignore. The framework delivers up to 70% accuracy gains while cutting token usage by roughly 39%. Critically, it lets smaller models match the output of larger systems without retraining, a scalability edge that matters in production environments. That same logic drives Google's AI budget optimization tools improving agent accuracy, where smarter resource allocation consistently outperforms raw compute.
⬤ The broader signal is clear: AI development is moving toward efficiency-first design rather than simply scaling model size. Frameworks like Plan and Budget lower operational costs while improving real-world performance, a direction reinforced by MIT studies on how LLMs learn reasoning more efficiently. As inference costs remain a pressure point, smarter token allocation may become as important as the models themselves.
 Peter Smith
Peter Smith


