 Peter Smith
Peter Smith

A new large-scale evaluation framework called MME-Emotion has been introduced by researchers from The Chinese University of Hong Kong, Tongyi Lab, SZTU, and Tencent. As 机器之心 JIQIZHIXIN reported, the benchmark tests emotional intelligence in multimodal large language models using over 6,000 curated video clips paired with structured questions - measuring both emotion recognition and reasoning, and representing a meaningful step forward in how we assess AI understanding of human behavior.
MME-Emotion Covers 8 Emotional Task Categories Across 27 Scenarios
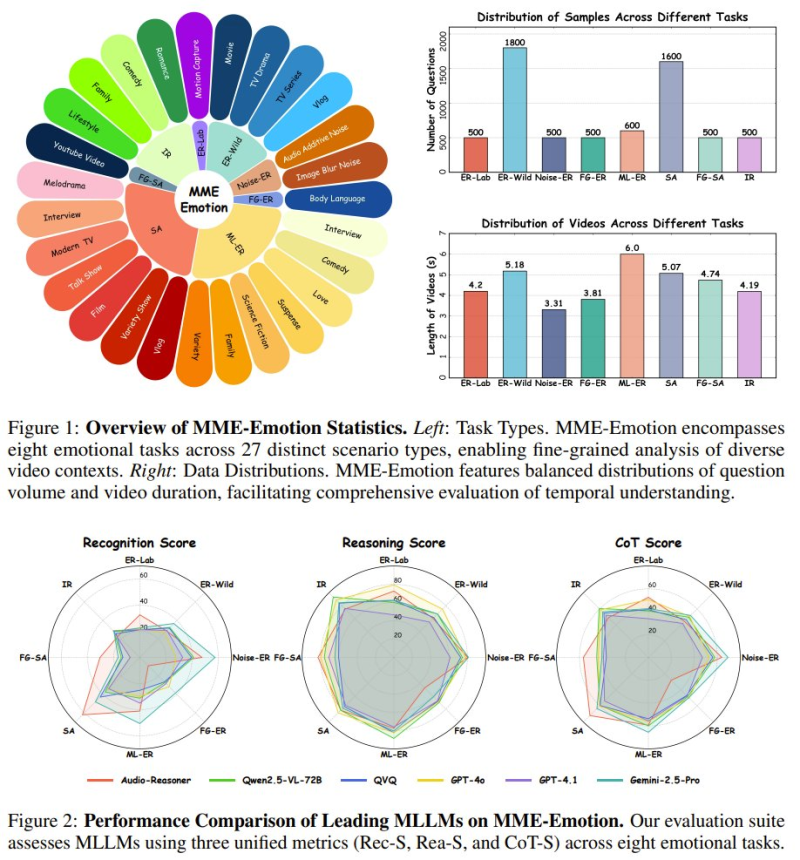
The benchmark spans a wide range of real-world contexts, including interviews, films, vlogs, and everyday social interactions.Balanced distributions of questions and video durations make evaluation consistent across all task types. Models are assessed using three unified metrics:
- Emotion recognition
- Emotion reasoning
- Chain-of-thought explanation
This structured approach sets MME-Emotion apart from earlier, narrower benchmarks that typically focused on a single dimension of emotional understanding.
Overall performance remains unsatisfactory, highlighting a significant gap in AI capabilities even as progress continues in related areas.
The broader AI adoption context - such as Google Gemini reaching 211 billion visits - makes rigorous evaluation frameworks like this increasingly relevant for developers and researchers alike.
Best AI Model Hits Only 39.3% Accuracy in Emotion Recognition Tests
The results make the challenge clear. The top-performing model managed just 39.3% accuracy in emotion recognition, with reasoning performance similarly limited. General-purpose multimodal models like GPT-4o show early signs of emotional understanding through broad training, while specialized models reach comparable numbers through targeted optimization.
General-purpose multimodal models demonstrate emerging emotional understanding through broad training, while specialized models achieve comparable results via targeted optimization.
Neither approach has come close to anything resembling human-level comprehension. Progress in AI is real but uneven - Mistral's speech model has been outperforming GPT-4o mini in adjacent benchmarks, which underscores how capability gains tend to cluster in narrow domains rather than across the board.
Why Emotional Intelligence in AI Matters Beyond Benchmarks
The findings point to a deeper challenge: moving AI systems beyond pattern recognition and logical reasoning into something that actually reflects human-centric understanding. As AI expands into communication tools, media analysis platforms, and interactive applications, emotional intelligence is becoming a core capability requirement. The uneven pace of progress is a recurring theme globally - Chinese AI leaders put a 20% chance on catching OpenAI in the near term. MME-Emotion gives researchers a more precise tool to track where the gaps actually are.
 Peter Smith
Peter Smith


