 Saad Ullah
Saad Ullah

Mistral AI has unveiled Mistral Small 4, a unified model that consolidates its flagship capabilities into a single architecture. With 128 experts, 119 billion total parameters, and a 256k context window, it targets developers who need both power and efficiency without juggling multiple systems.
40% Faster With Configurable Reasoning
The headline numbers are hard to ignore. Mistral Small 4 is 40% faster than its predecessors and delivers up to three times higher throughput. Configurable reasoning lets developers dial in how the model processes tasks, adding flexibility that static models cannot offer.
This follows a clear pattern in Mistral's roadmap, which previously included the release of Ministral 3 models built with cascade distillation.
Released under the Apache 2.0 license, Mistral Small 4 continues the company's commitment to open deployment. This approach removes vendor lock-in and makes the model accessible to teams building everything from internal tools to customer-facing products.
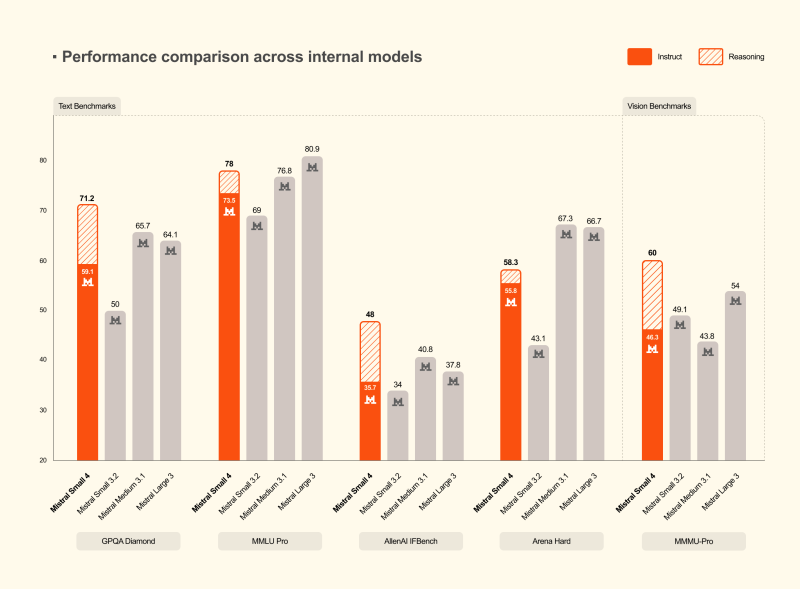
Benchmark Results Show Competitive Edge Across Text and Vision
On datasets including MMLU Pro, GPQA Diamond, and Arena Hard, Mistral Small 4 posts strong numbers, especially when reasoning mode is active. The results position it between lean models and heavyweight alternatives, offering a meaningful cost-to-performance trade-off. These advances in core model capability align with parallel progress in how AI systems handle agent memory through 4-layer infrastructure.
By merging multimodal text and vision capabilities into one deployable system, Mistral AI is cutting complexity for builders while raising the performance ceiling. The company has been expanding aggressively on multiple fronts, and its speech model that beats GPT-4o mini with a 4% error rate shows the same optimization-first thinking driving Small 4. If throughput and cost efficiency are the benchmark, this release is a serious contender.
 Saad Ullah
Saad Ullah


