 Victoria Bazir
Victoria Bazir

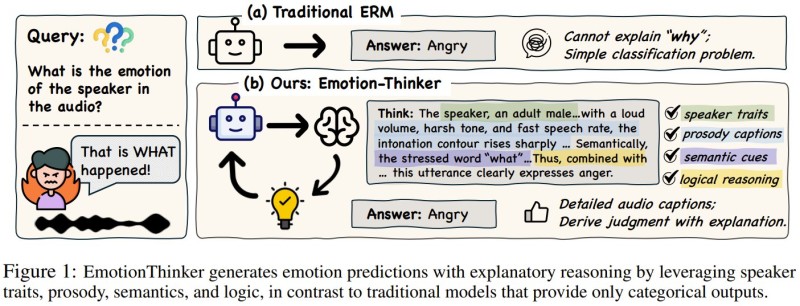
Microsoft researchers, working with The Chinese University of Hong Kong, have introduced a new speech AI framework called EmotionThinker. Designed to improve transparency in speech emotion recognition, the model shifts emotion detection away from simple categorical labeling toward structured, reasoning-based explanations. Instead of outputting just "angry" or "happy," EmotionThinker analyzes speech patterns and describes exactly why it reached a particular conclusion.
Traditional speech emotion recognition systems work as black-box classifiers: they process audio and return a single label, with no insight into the decision process. EmotionThinker breaks from this approach by evaluating multiple features within the audio signal simultaneously, including speaker traits, prosody patterns such as pitch and rhythm, semantic cues, and logical reasoning steps, before arriving at a final prediction.
How EmotionThinker Uses Reinforcement Learning to Reason Through Emotions
The model is trained on a specialized dataset designed to capture subtle emotional signals in speech and is optimized through reinforcement learning methods that reward both prediction accuracy and reasoning quality. By focusing on fine-grained acoustic cues, EmotionThinker generates detailed explanations describing how voice characteristics influence emotional interpretation. According to the research, this approach improves both accuracy and explanation quality compared with existing models.
Similar work exploring how AI systems explain their logic is documented in recent research on large-scale AI reasoning benchmarks, which examines how modern models are increasingly built to justify their outputs rather than simply produce them.
Explainability Becomes a Core Benchmark for Next-Generation Speech AI
EmotionThinker reflects a broader shift across AI research, where transparency and interpretability are becoming as important as raw performance. As AI systems take on increasingly complex real-world tasks, the ability to explain reasoning rather than just deliver a result is moving from a niche concern to a core design requirement.
Infrastructure investment is accelerating in parallel, as rising AI workloads push hardware and semiconductor demand to new highs. The development of EmotionThinker positions Microsoft and The Chinese University of Hong Kong at the forefront of this transition, building speech AI that can interpret tone, rhythm, and linguistic context while making its reasoning visible and auditable.
 Victoria Bazir
Victoria Bazir


