 Usman Salis
Usman Salis

Large language models are getting smarter, but keeping them efficient in real conversations remains a genuine engineering challenge. A team from Zhejiang University, the National University of Singapore, and Nanjing University has introduced LightMem, a memory architecture that rethinks how AI systems store and retrieve conversational context. The goal: keep responses fast without burning through computational resources.
Traditional memory-augmented AI systems tend to loop through raw conversation data repeatedly, which drives up both latency and cost. LightMem takes a different approach, one loosely inspired by how human memory works.
How LightMem's Three-Stage Memory Structure Works
The architecture runs on three layers: a sensory filtering stage that removes redundant input early, a topic-based short-term memory module that organizes context by subject, and a long-term memory component updated during an offline "sleep phase." That last part is key. By pushing complex memory consolidation to an offline process rather than handling it during live inference, the system keeps real-time responses snappy while still maintaining rich conversational context.
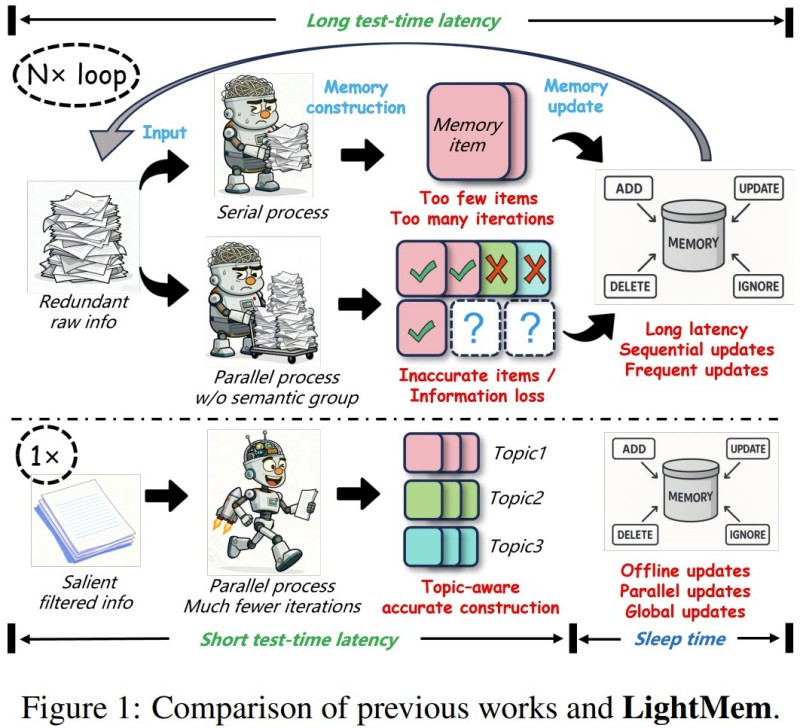
The efficiency numbers are striking. On the LONGMEMEVAL and LOCOMO benchmarks, LightMem improved accuracy by up to 29% in certain scenarios while reducing API calls by up to 310x and token usage by up to 117x compared to baseline approaches. That kind of reduction reflects a fundamental restructuring of when and how memory processing happens, not minor optimization.
Why LLM Memory Efficiency Is Becoming a Core Engineering Priority
As conversational AI moves deeper into enterprise software and automation pipelines, the cost of keeping those systems responsive at scale is a real constraint. Infrastructure overhead and latency aren't just developer concerns; they directly affect what products can be built and at what price point. This connects to a broader pattern where AI platforms are competing not just on capability but on long-term value delivered to users and businesses.
Research like LightMem reflects a growing shift in how the field measures AI progress, where the focus is moving beyond benchmark scores toward systems that reason well and operate efficiently at the same time. Memory-augmented generation is still evolving, but architectures that cut overhead without sacrificing capability could shape how the next generation of AI platforms is designed and deployed.
 Usman Salis
Usman Salis


