 Eseandre Mordi
Eseandre Mordi

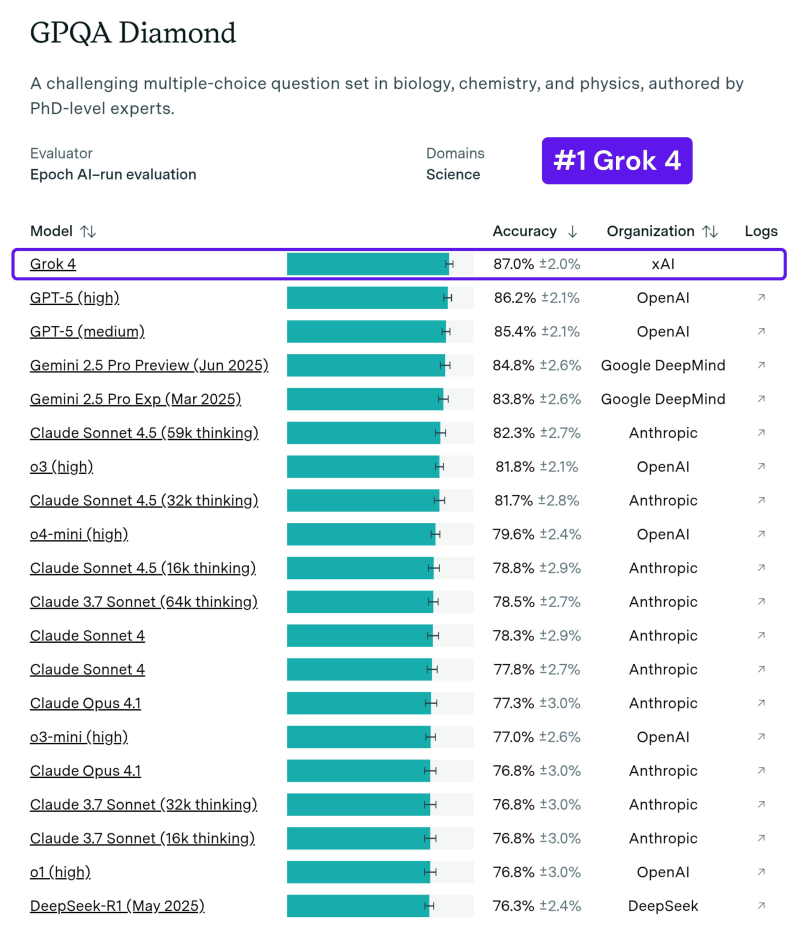
● Grok 4 now leads the GPQA Diamond rankings with an 87.0% score, outperforming GPT-5, Gemini 2.5 Pro, Claude Sonnet 4.5, and other frontier models on advanced scientific reasoning tasks.
● In a recent announcement, X Freeze revealed that Grok 4 has taken the #1 spot on the GPQA Diamond leaderboard—one of AI's most demanding science benchmarks. The evaluation features "the hardest science questions things even experts find tough," making it a true test of scientific reasoning rather than simple pattern matching. He noted that Grok 4 "shows real intelligence where it matters most."
● The results also reveal growing pressures across the AI sector. As teams compete to match Grok 4's performance, the challenge is raising the bar for compute power and development resources. Industry observers worry that smaller labs may fall behind, potentially driving consolidation and talent migration toward well-funded organizations. Without adequate support, many teams could struggle to compete where scientific accuracy becomes the key differentiator.
● Still, Grok 4's achievement shows that breakthroughs are happening fast. The model scored 87.0% ±2.0%, surpassing GPT-5 (high), multiple Gemini 2.5 Pro versions, Claude Sonnet 4.5, o3-series models, and other major systems. The GPQA Diamond chart confirms Grok 4's clear lead across all categories.
● For those following AI development, this ranking signals an important shift: scientific reasoning benchmarks are becoming critical measures of real intelligence, and Grok 4's top score positions it as a leading choice for serious scientific work.
 Eseandre Mordi
Eseandre Mordi


